Triquetra for LoRA's entangled knobs: When LoRA rank changes, how should learning rate move?
Different choices of alpha(r) lead to different learning-rate transfer patterns.

LoRA [1] exposes three knobs that are tied together: rank r, scale alpha, and learning rate lr. In practice, people usually change rank first because of memory limits, speed, or an intuition about adaptation capacity. Then they tune lr again.
So the practical question is narrower than "what is the best LoRA learning rate?"
It is this:
When rank changes, where should the learning-rate search move?
Our answer is that it depends on how alpha scales with rank. There is no single transfer story that holds across all LoRA setups. Change the scaling rule, and the way learning rates transfer across rank changes with it.
In our experiments, four patterns stand out:
- If
alpha/ris fixed, higher rank usually wants a smaller learning rate, and the usable region moves downward. - If
alphais fixed, higher rank does not automatically push you toward smaller learning rates, and a reusable cross-rank band often shows up. - If
alpha ∝ sqrt(r), reusing the same order of learning rate is the most natural outcome from the simple theory, and it matches the rank-stable scaling highlighted by rsLoRA [3]. - In the harder
Qwen3-4B + MATHtransfer setting,alpha ∝ sqrt(r)also gives the best high-rank behavior overall.

That last point matters. The real question is not whether one learning rate remains reusable everywhere. It is which scaling rule gives you a learning-rate region you can keep using as rank changes.
All figure-level empirical claims in this post come from the repository's rank-by-learning-rate sweeps. The external references below are for the LoRA parameterization, transfer framing, and model/dataset provenance.
A small theory model already gives three transfer stories
The easiest place to think about rank dependence is the start of training.
Following LoRA, we parameterize the update as
Under the standard initialization, is randomly initialized while . As a result, at the very beginning of training we have , and the gradients behave asymmetrically: the gradient w.r.t. is zero (because it is proportional to ), while the gradient w.r.t. is non-zero (because it depends on ). Therefore, the first effective movement comes entirely from updating .
Consider a single gradient update with learning rate . The update to scales as
so in terms of magnitude we can write
Substituting this back into , the first non-zero perturbation becomes
At initialization, is random with approximately independent rows, so the matrix product aggregates contributions across the rank components and scales like . Combining terms, we obtain
This quantity serves as a simple proxy for the effective step size induced by one update. It is not meant to exactly describe AdamW dynamics, but it captures how the aggressiveness of the update changes with rank.
In particular, if the quantity increases with rank, the resulting updates become effectively more aggressive, suggesting that smaller learning rates may be needed at higher ranks. Conversely, if this quantity decreases with rank, the updates become more conservative, and increasing rank does not require reducing the learning rate.
More broadly, this reflects a general principle: we would like hyperparameters (such as the learning rate) to transfer smoothly across changes in model size or parameterization. This idea is closely related to Transfer [2].
At the same time, this one-step analysis is only a simplification. In practice, optimizers like AdamW adapt updates differently across parameters. In particular, as emphasized by LoRA+ [4], the two factors and can benefit from different effective learning rates, meaning that the full optimization dynamics are richer than what this simple proxy suggests.
From there, the three common scaling rules split pretty quickly:
- If
alpha/ris fixed, thenalpha_r ∝ r, so the effective update grows with rank. Higher rank should push the search toward smaller learning rates. - If
alphais fixed, then the effective update shrinks with rank. Higher rank should not force smaller learning rates. - If
alpha ∝ sqrt(r), the rank dependence cancels. This is the simplest route to reusing the same order of learning rate, and it is also the scaling singled out by rsLoRA [3].
If you plot that proxy over rank × lr, the three rules look obviously different:

Under fixed alpha/r, the surface tilts upward with rank, so the same learning rate becomes more aggressive as rank grows. Under constant alpha, it tilts the other way, so the same learning rate becomes more conservative. Under alpha ∝ sqrt(r), it stays flat in the rank direction. That is why the simple theory points to it as the most stable same-order transfer rule.
That is the whole model for the rest of the post. We are not claiming one universal learning rate. We are claiming that different alpha(r) choices create different transfer behavior.
AG News is the easiest place to see it in the data
We use AG News [6] as the evaluation task because, in this setting, the optimal learning rate lies within the interior of the search grid rather than at its boundary. This avoids edge effects and makes it easier to interpret how performance varies with the learning rate. All experiments are conducted in a DistilBERT [5] classification setup, where we sweep over learning rates and observe how the optimal choice shifts under different configurations.
We swept LoRA rank over 2, 4, 8, 16, 32, 64, 128, 256 and compared three scaling rules:
- constant
alpha=32 - fixed
alpha/r = 1 alpha ∝ sqrt(r)withalpha/sqrt(r)=8
Start with the heatmaps.

With fixed alpha/r, the best-learning-rate region and the cluster of strong cells slide downward as rank increases. That is exactly the directional shift the scaling argument suggests.
With constant alpha, the picture changes. The best point barely moves across rank, and the high-performing band stays much flatter. In this sweep, it is the easiest rule to tune when the goal is simple cross-rank reuse.
alpha ∝ sqrt(r) lands between those two. It mostly preserves same-order learning-rate reuse, which is what the simple scaling rule would lead you to expect.
Each panel uses its own grayscale range, so brightness comparisons only make sense within a panel. What matters is where the strong cells sit and how that location changes with rank.
The curve view makes that easier to see.

These rank curves tell the same story more clearly. Fixed alpha/r shifts the good part of the curve family toward smaller learning rates as rank grows. Constant alpha keeps the peak region much flatter. alpha ∝ sqrt(r) still preserves same-order reuse, though in this particular sweep constant alpha ends up slightly flatter in practice.
That is the main AG News result. Learning-rate transfer is not universal. It depends on the scaling regime you picked.
There is also a distinction here that is easy to blur if you move too fast:
- Constant
alphais the flattest rule in this experiment alpha ∝ sqrt(r)is the simplest rule from the theory
Those are related claims, but they are not the same claim.
Qwen3-4B on MATH makes the differences harder to ignore
We then moved to a tougher setting:
- model:
Qwen/Qwen3-4B-Instruct-2507[7] - train set:
MATH \ MATH500[8] - evaluation:
MATH500, AIME24, AIME25 - ranks:
2, 8, 32, 128
This sweep is more informative than a simple "everything wants a lower LR" story. The useful region collapses into the sub-1e-6 range, and the scaling rules separate much more sharply at high rank.
The heatmaps show the first part right away.
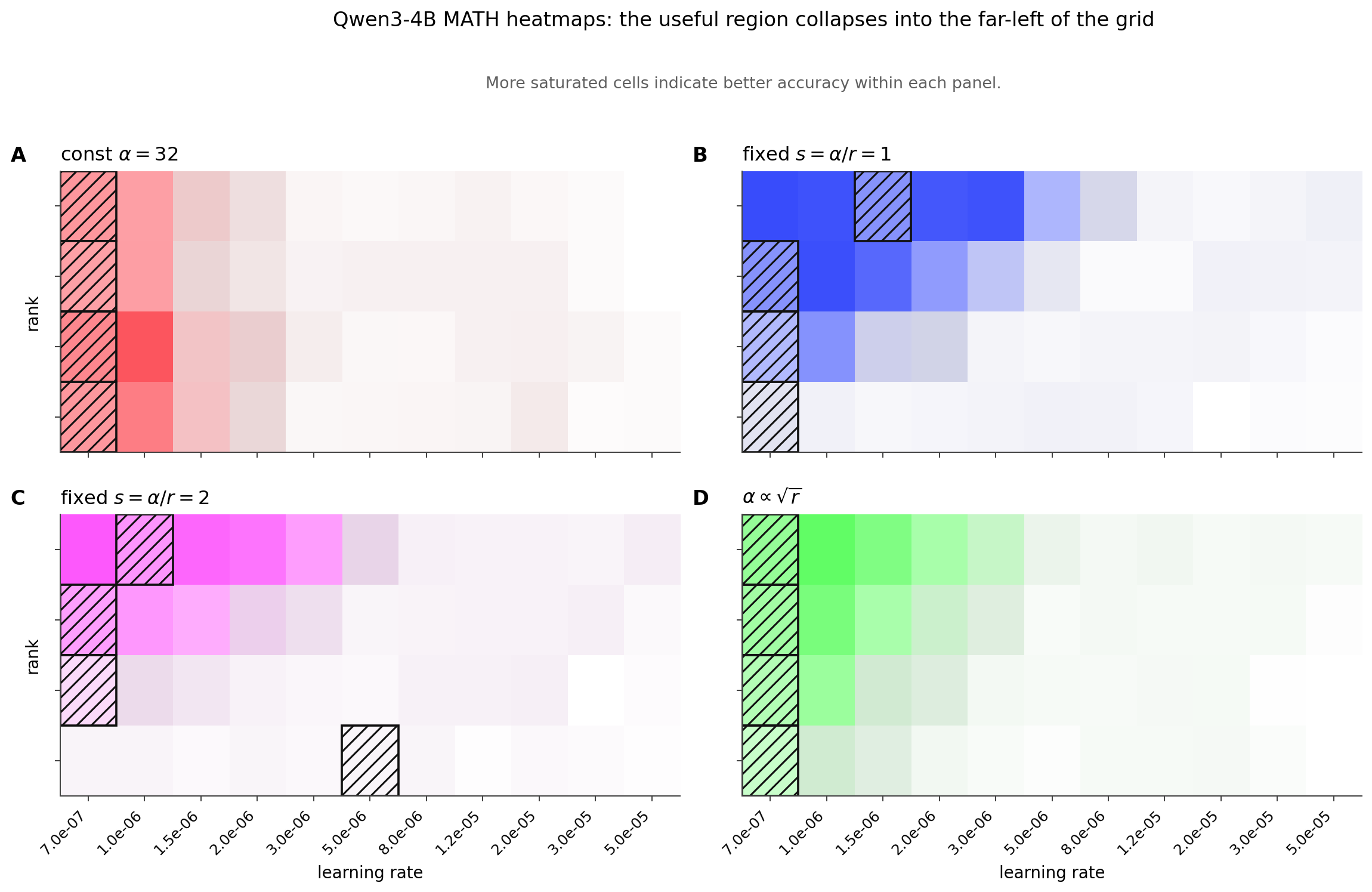
Almost all of the useful area gets squeezed against the far-left side of the grid, around 7e-7. But even when several protocols land on that same low learning rate, they do not behave the same way once rank gets large.
As with AG News, brightness comparisons only make sense within a panel. The interesting part is the left-edge concentration and where each panel's best cells end up.
The curve view makes the second point more obvious.

Constant alpha stays remarkably flat: across ranks, it repeatedly selects almost the same very small learning rate. But flatness alone is not enough. In this setting, it is not the strongest rule overall.
By contrast, fixed alpha/r can perform very well at low rank, especially with aggressive choices such as alpha/r = 2. However, its performance deteriorates quickly as rank increases, and this decline is especially visible on the hardest evaluations.
Among the rules considered here, alpha ∝ sqrt(r) is the most balanced. It not only preserves exact best-point reuse throughout this sweep, but also delivers the strongest overall performance as rank grows. If we had to choose a single rule based on these plots, this would be the natural starting point.
This distinction is important because best-point reuse and transfer quality capture different things. Best-point reuse asks whether the same learning rate remains optimal after changing rank, whereas transfer quality asks whether performance remains strong when that learning rate is reused. A rule can therefore appear flat in the first sense while still performing poorly in the second. That is exactly what this MATH setting reveals.
So compared with AG News, the harder transfer setting changes the picture. Here, the theoretically motivated rule is not just aesthetically appealing or easy to justify. It is also the strongest practical choice once high-rank performance becomes important.
What we would do in practice
If we are changing LoRA rank in a real sweep, we would not start from the idea that one learning rate should work everywhere. We would start by asking which alpha(r) rule we are committing to, because that already tells us how much transfer to expect.
A simple playbook:
As the easiest engineering default
Start with constant alpha.
In our sweeps, it gives the flattest behavior in the narrow sense that the best learning-rate location moves very little with rank. If we want a simple tuning story, this is a strong default.
As the simplest transfer rule
Start with alpha ∝ sqrt(r).
That is the most natural rule under the early-training scaling argument, and in the harder Qwen3-4B MATH setting it is also the best high-rank choice overall.
Under fixed alpha/r
Do not assume the same learning rate will keep working as you move upward in rank.
When rank increases, search lower first. On harder reasoning tasks in particular, fixed alpha/r can still look good at low rank and then deteriorate quickly at high rank.
The useful object is a reusable band, not one magic learning rate
People often frame transfer as a yes-or-no question: does the same best learning rate work everywhere?
We do not think that is the right level to look at it.
The more useful object is the reusable learning-rate band.
Different scaling rules give that band different shapes across rank:
- fixed
alpha/rpushes it downward - constant
alphakeeps it roughly flat alpha ∝ sqrt(r)preserves same-order reuse and ends up strongest in the harder math setting
So we would not summarize this as "LoRA has one universal learning rate," because that is not what the results say. What the results say is simpler: rank changes get much easier to reason about once we stop hunting for one global optimum and start asking which scaling rule gives us a band we can actually reuse.
References
[1] LoRA: Low-Rank Adaptation of Large Language Models (Hu et al, 2021)
[2] Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer (Yang et al, 2022)
[3] A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA (Kalajdzievski, 2023)
[4] LoRA+: Efficient Low Rank Adaptation of Large Models (Hayou et al, 2024)
[5] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (Sanh et al, 2020)
[6] Character-level Convolutional Networks for Text Classification (Zhang et al, 2015)
[7] Qwen3 Technical Report (Yang et al, 2025)
[8] Measuring Mathematical Problem Solving With the MATH Dataset (Hendrycks et al, 2021)
Author
Mind Lab
Core Contributors
Di Zhang, Kyrie Lei, Ruijia Zhang, Kieran Liu, Andrew Chen, Pony Ma
Team
Andrew Chen, Kaijie Chen, Song Cao, Cleon Cheng, Steven Chiang, Nolan Ho, Charles Huang, Fancy Kong, Kyrie Lei, Andrew Lei, Lucian Li, Ray Li, Theo Li, Logan Liu, Kieran Liu, Irvine Lu, Pony Ma, Vincent Wang, Guikun Yang, Rio Yang, Regis Ye, Alex Yin, Di Zhang, Ruijia Zhang, Conley Zhao, Congjie Zheng, Murphy Zhuang and Mindverse Team
Names are listed alphabetically within team.
Citation
Please cite this work using the BibTeX citation:
@misc{zhang2026triquetraforlora, author = {Di Zhang and Kyrie Lei and Ruijia Zhang and Kieran Liu and Andrew Chen and Pony Ma and {Mind Lab}}, title = {Triquetra for LoRA's entangled knobs: When LoRA rank changes, how should learning rate move?}, year = {2026}, howpublished = {Mind Lab: A Lab for Experiential Intelligence}, note = {https://macaron.im/mindlab/research/triquetra-for-loras-entangled-knobs-when-lora-rank-changes-how-should-learning-rate-move} }