0.03% Parameters, 100% Potential: Reflexivity of Compute Optimal Rank Scaling
Why the Next LoRA Win May Be Smaller, Not Larger: Low rank already shows real potential. Mid rank is the stable default. High rank gets more expensive without opening a better frontier.
Low-rank LoRA in reasoning RL already shows meaningful signal. In our Qwen3-8B PPO sweep, rank 16 to 32 remains the most stable operating region. But the same sweep also suggests a different research conclusion: the most interesting open question may lie on the low-rank end of the rank curve, rather than in pushing father into the high-rank end.
Our LoRA rank sweeps in reasoning RL get summarized with the sentence: there is a sweet spot in the middle. That is a reasonable deployment summary. It is not, however, the only useful reading of the data [1] [2] [3].
The same sweep also shows two additional facts. First, rank 1 to 4 remains viable in part of the space. Second, rank 64 to 256 does not open a better frontier in the observed runs. Taken together, these observations shift the question. Instead of asking how far to increase rank, it becomes more useful to ask how small the adapter can be before the recipe becomes unreliable, why that failure mode appears, and what would be required to remove it.
That is the scale-down reading of the sweep. The deployment answer remains in the middle. The research agenda points towards smaller ranks.
TL;DR
- Rank 16 to 32 is still the right default if the goal is dependable performance today.
- Rank 1 to 4 already shows positive signal, which means the low-rank regime looks under-optimized rather than fundamentally impossible.
- Rank 64 to 256 appears saturated in the observed sweep: footprint keeps rising, but the frontier does not improve.
- Mean score and best score answer different questions: mean measures reliability across seeds, while best measures single-run upside within the same seed set. The gap between them is one of the clearest ways to identify latent upside versus true reliability.
- The next meaningful win is likely to come from making tiny adapters stable, not from making large adapters larger.
Why this question matters
LoRA matters in post-training for operational reasons, not just because it uses fewer trainable parameters in principle. Smaller adapters mean less optimizer state, lighter checkpoints, and less memory pressure during RL. They also make it easier to keep many candidate adapters around at once, which is useful when the real bottleneck is experimentation rather than raw model capacity [1] [4] [6].
That matters even more in reasoning RL than it does in ordinary supervised finetuning. RL is variance-sensitive. Progress often requires more seeds, more ablations, more reward debugging, and more prompt coverage than we can comfortably afford. A smaller trainable footprint is not just a systems convenience. It can change the economics of the research loop [2] [7] [8].
This is why the low-rank end of the rank curve matters [4]. If very small adapters can become reliable, then the same budget can do more repetition, and more repetition is exactly what fragile regimes tend to need. In that sense, scale-down research is partially reflexive: making each run cheaper can make it easier to discover the recipe that the small regime needs [2] [5] [6].
Experimental basis
This post is grounded in a Qwen3-8B PPO rank sweep covering 216 runs: 9 LoRA ranks, 4 batch sizes, and 6 seeds per setting [2] [3]. The low-rank, mid-rank, and high-rank interpretation is empirical for that sweep. When we discuss downside risk below, we mean downside observed within those runs.

Figure 1. The 8B sweep re-read as a scale-down problem. Low rank already contains real signal, mid rank is the dependable operating window, and high rank loses efficiency without opening a better frontier.
Read the curve in three bands
Low rank already has signal
The strongest reason to treat this as a scale-down problem is simple: low rank already works in part of the space. At rank and batch , the sweep still shows a positive mean gain of , or about percentage points, with no negative-gain runs observed in seeds at that setting. Move one step up and the pattern becomes clearer. Rank stays positive at all four batch sizes, with mean gains ranging from to . Rank is stronger still, ranging from to . This is not the pattern of a uniformly failing regime. It is the pattern of a regime that remains viable but insufficiently robust.
This distinction matters. If the entire low-rank region were uniformly negative, the most natural conclusion would be that the adapter is simply too small for the task. But that is not what the curve says. The curve says that even very small adapters can point in the right direction, just not yet with the level of stability that would make them a serious replacement for the middle.
That is why low rank should be read as a recipe problem before it is read as a capacity limit. Small adapters face three pressures at once: narrow update capacity, RL variance, and hyperparameters that are often inherited from larger-rank settings. If any of those are mismatched, a small positive signal can disappear before it becomes repeatable.
Mid rank is the current default
The middle of the curve still matters, because it is where the recipe becomes boring in the good way. Rank and rank are almost tied on mean gain, at and . They also show no negative-gain runs across runs in the sweep. That combination is what makes them the current deployment answer.
This is also where the Pareto framing becomes useful. Real decisions are not made on score alone. They are made on score subject to cost, throughput, and risk. In the current sweep, the non-dominated choices remain in the same mid-rank family. That means rank to is not just where the best average numbers happen to land. It is where the operating tradeoff is cleanest [4].

Figure 2. The practical target is the Pareto frontier, not a single best score. Across token budgets, the non-dominated configurations remain in the mid-rank family.
The right way to use this result is as a benchmark, not as an excuse to stop asking questions. Rank to is the setting that low-rank research needs to catch. It is the dependable reference point against which a smaller adapter should be judged.
High rank is where cost outruns value
The right side of the curve is much less interesting than it first appears. Mean gain falls from about percentage points at rank to at rank , at rank , and at rank . Once the middle is reached, pushing rank upward mostly buys extra footprint rather than extra value.
Some of that cost is obvious: more trainable parameters, more optimizer state, larger checkpoints, and more memory pressure. But the more important cost is opportunity cost. Every unit of rank that fails to improve the frontier is budget that could have been spent on more seeds, more tasks, more ablations, or more careful work on the fragile left edge.
Some of that cost is obvious: more trainable parameters, more optimizer state, larger checkpoints, and more memory pressure. But the more important cost is opportunity cost. Under a fixed research budget, moving from rank to rank reduces the simulated experiment capacity from to seed-runs, and moving to rank reduces it to seed-runs, even though the observed mean gain does not improve. In other words, every unit of rank that fails to improve the frontier is budget that could have been spent on more seeds, more tasks, more ablations, or more careful work on the fragile low-rank regime.

Figure 3. A fixed-budget view makes that opportunity cost concrete.
This is why the high-rank region should not automatically be treated as the ambitious end of the search space. In this sweep it looks mostly saturated. It is the part of the curve that warns against a default assumption that more rank must mean more progress.
Mean score and best score are different signals
One of the most useful ways to read a rank sweep is to separate mean score from best score. Here mean score is the average final evaluation score across 6 seeds for one configuration, while best score is the strongest single-seed final score from the same set of runs. Best score therefore answers a possibility question: can this regime ever reach a strong solution under the current recipe? Mean score answers a reliability question: does the recipe reach that solution consistently?
When best score is already competitive at low rank while mean score still lags, that is evidence of latent upside. The capacity to do something useful may already exist, but the recipe is not reliably accessing it. By contrast, when both mean and best flatten on the right, there is little reason to believe that more rank is hiding a better story.
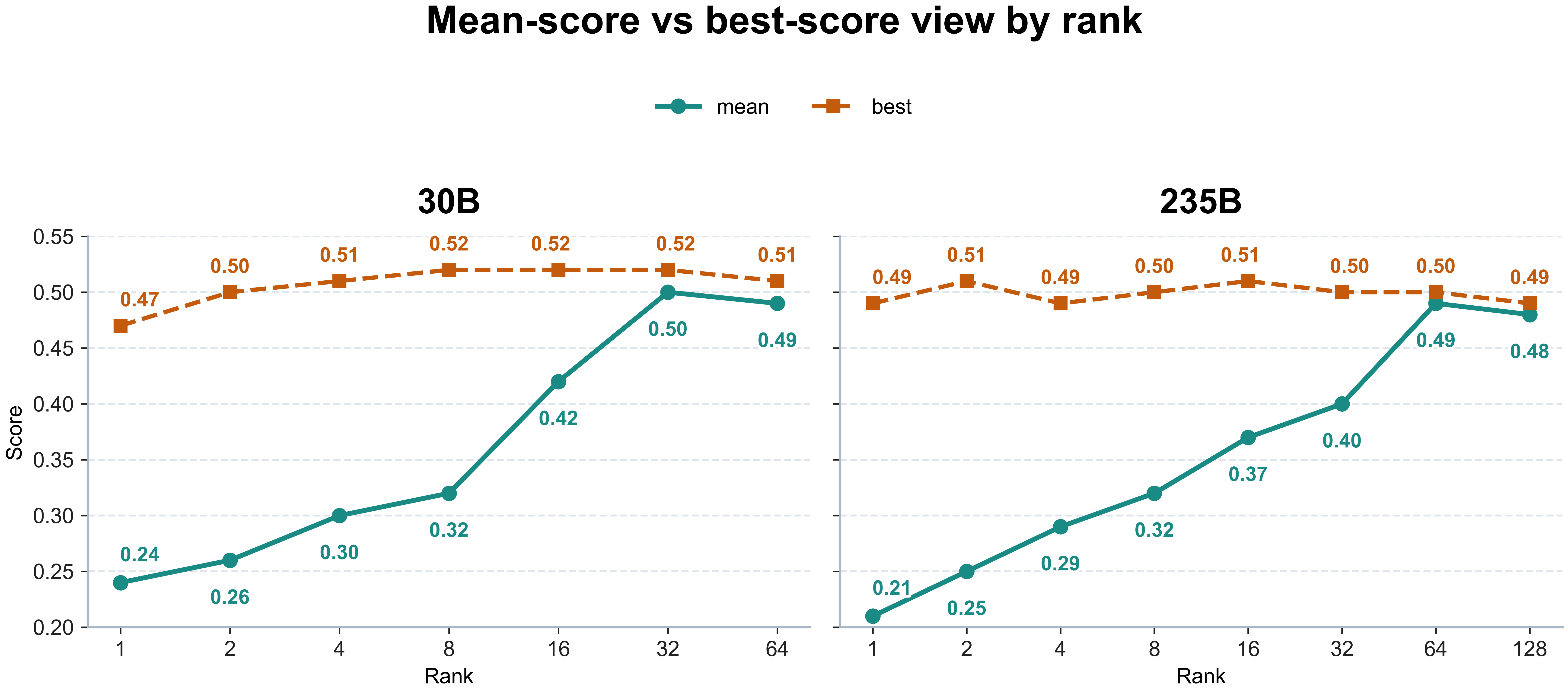
Figure 4. The 30B and 235B mean-score versus best-score view illustrates the main interpretive point: low rank can have upside before it has reliability, while the far right often stops opening a new story.
That is why Figure 3 matters. It sharpens the distinction between signal and stability. If a low-rank configuration wins only on its best run, then it is not yet a deployment candidate. But it may still be the most important research candidate, because it shows that the regime is not empty. The work is to close the mean-best gap.
This is also why the mid-rank region looks so strong. The middle does not just post high mean performance. It narrows the gap between what is possible and what is repeatable. In RL, that narrowing is often the difference between an interesting experiment and a usable method.
Why Smaller Adapters Remain the More Interesting Research Direction
The 0.03% parameters is interesting not because it makes for a provocative title, but because it points to a cheaper research loop. A tiny adapter that is not yet fully reliable can still be more important than a larger adapter that is merely adequate, if the smaller one points to a more scalable path.
The operational benefits stack up quickly. A smaller adapter means cheaper runs, lighter storage, easier checkpoint management, and more room to spend compute on the parts of RL that actually reduce uncertainty. It also improves the feasibility of exploring larger base models under fixed hardware constraints, because the trainable slice and its optimizer state stay manageable.
Most importantly, it changes how many times we can try. That matters because fragile regimes do not usually become reliable through one lucky seed. They become reliable through sustained iteration: seed-heavy evaluation, better initialization, cleaner optimization, better variance control, and more thoughtful parameter allocation.

Figure 5. Trainable footprint grows directly with LoRA rank. Moving left does not only change modeling capacity; it also buys cheaper optimizer state, lighter checkpoints, and more room for iteration.
There is also a feedback effect here. If scaling down makes each attempt cheaper, it becomes easier to run exactly the repeated experiments that the low-rank regime seems to need. Lower-rank LoRA is not only a target for efficiency. It may also be a vehicle for faster methodological progress.
What we would test next
The current sweep is enough to define the agenda, even if it does not yet solve it. A serious scale-down program would prioritize a short list of interventions.
- Better initialization. If low rank is already near a useful update subspace, initialization may matter far more than it does in an overparameterized regime.
- Low-rank-specific optimization. Learning rate, LoRA scaling, KL schedule, clipping, and optimizer settings may need to be matched to rank or .
- Stronger variance control. Reward noise, batch effects, and early instability can erase a small positive signal. The left edge should benefit disproportionately from tighter control.
- Structured parameter allocation. Uniform rank everywhere may be the wrong object. Mixed-rank or layerwise allocation could preserve a tiny overall footprint while giving more freedom to the layers that matter most.
- Seed-heavy evaluation. If the claim is that low rank is fragile rather than empty, then sparse evaluation will systematically misread the regime.
The important point is not that rank is already the answer. It is that rank to is the part of the curve where methodological progress is most likely to pay off.
Conclusion
Existing conclusion of LoRA rank in reasoning RL is that there is a sweet spot in the middle. The better summary is that there is a deployment sweet spot and a separate research agenda.
The deployment answer is still mid rank. The research answer is smaller, not larger. Low rank already has enough signal to be worth fighting for, and high rank already looks too expensive for the value it returns. The next meaningful win is therefore unlikely to come from another move to the right. It is more likely to come from turning the tiny-adapter regime from a lucky run into a reliable recipe.
If that happens, the importance of 0.03% parameter will not be that it sounded provocative in a title. It will be that a vanishingly small trainable slice became a practical lever for scaling reasoning RL more intelligently.
Appendix: Experimental Setup
We summarize a full sweep over:
- Base model:
Qwen3-8B[3] - Algorithm:
PPO[2] - Training schedule:
500PPO steps - LoRA ranks:
1, 2, 4, 8, 16, 32, 64, 128, 256 - Batch sizes:
16, 32, 64, 128 - Seeds:
6per configuration - Total runs:
9 x 4 x 6 = 216
The training data is a mixed mathematics corpus with about 24,000 training examples and 1,330 evaluation examples, spanning GSM8K, MATH, OpenR1, DAPO, Nemotron, OpenThoughts, and AIME-style subsets. We use verifiable rewards: correctness is primary, boxed-answer formatting receives a small bonus or penalty, and output length receives a light regularization term [7] [8].
One methodological point is critical: this sweep fixes the number of PPO steps, not the total number of training tokens. As batch increases, token consumption also increases. That means the batch axis should be interpreted as a score-cost trade-off, not as a clean causal estimate of batch size alone.
Appendix: Additional Quantitative Notes
A1. Low Rank Is Viable, but Not Stable
Even rank 1 remains trainable at batch 16, yielding a positive mean gain of +0.0154 and no observed negative-gain runs across seeds. But low rank is not broadly safe under the current recipe. The same rank configuration becomes fragile as batch grows:
rank=1, batch=32: mean gain+0.0112, negative-gain risk16.7%rank=1, batch=64: mean gain-0.0012, negative-gain risk50.0%rank=1, batch=128: mean gain-0.0185, negative-gain risk66.7%
The appropriate conclusion is therefore not that "extreme low rank is enough." It is that low-rank LoRA can capture useful RL updates under favorable conditions while operating with a very limited safety margin [1] [4].

Figure A1. Low rank remains trainable in part of the space, but its viable region is narrow. Mid-rank LoRA stays positive across a much wider range of settings.
A2. Larger Batch Buys Ceiling, Not Efficiency
If we average over rank and only look at batch families, larger batches do reach slightly higher mean final scores:
batch=16: mean gain+0.0645batch=32: mean gain+0.0683batch=64: mean gain+0.0747batch=128: mean gain+0.0760
Read in isolation, this can make large batch look strictly better. But once token cost is included, the picture changes sharply:
- Training tokens rise from
48Matbatch=16to285Matbatch=128 - Token efficiency falls from
0.001344to0.000267 - Negative-gain risk rises from
0%to11.1%
In other words, moving from batch=16 to batch=128 buys only about +1.15 score points of extra mean gain, but costs nearly 6x more tokens and introduces visible downside risk. That is a budget decision, not an automatic upgrade [4].

Figure A2. Larger batch raises the score ceiling in this fixed-step sweep, but it also widens uncertainty and makes the gain much more expensive.
A3. Rank Has a Clear Sweet Spot
Rank behaves very differently from the naive "more capacity is always better" story. At the family level, mean gain rises quickly from very low rank, peaks in the mid-rank regime, and then declines:
rank=1: mean gain+0.0017, negative-gain risk33.3%rank=16: mean gain+0.1012rank=32: mean gain+0.1019rank=256: mean gain+0.0534, negative-gain risk4.2%
The peak is not broad in an uninformative sense. It is structurally meaningful. Rank and rank are the best region on both mean gain and token efficiency, while rank and above do not extend the frontier. In the Pareto view, rank is the non-dominated configuration at every token budget in this sweep.

Figure A3. Mean gain peaks at mid rank rather than increasing monotonically. More adapter capacity does not automatically translate into better RL outcomes under a finite PPO budget.

Figure A4. The same mid-rank regime is also the most efficient one. Higher rank spends more capacity without earning proportional return.
A4. Distribution Matters More Than a Single Best Run
This is why the sweep uses six seeds per configuration. The purpose of multi-seed evaluation is not to make the model more stable. It is to make the conclusion more honest.
A configuration with a strong best run can still be a poor default if its lower tail is bad. That is exactly why negative-gain risk is useful: it measures how often RL finishes below the base model, not just how high the average can go.
The contrast is sharp in this sweep:
rank=32, batch=16has mean gain+0.0855, standard deviation0.0073, and0%negative-gain riskrank=1, batch=128has mean gain-0.0185, standard deviation0.0380, and66.7%negative-gain risk
This is not a cosmetic difference. It is the difference between a configuration you can ship as a default and one you can only justify as an edge-case experiment.

Figure A5. The important distinction is not only where the mean sits, but how wide the distribution is and whether the lower tail crosses below zero.
References
[1] LoRA: Low-Rank Adaptation of Large Language Models (Hu et al, 2021)
[2] Proximal Policy Optimization Algorithms (Schulman et al, 2017)
[3] Qwen3 Technical Report (Yang et al, 2025)
[4] LoRA Without Regret (Schulman and Thinking Machines Lab, 2025)
[5] LoRA vs Full Fine-tuning: An Illusion of Equivalence (Shuttleworth et al, 2025)
[6] LoRA Learns Less and Forgets Less (Biderman et al, 2024)
[7] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI et al., 2025)
[8] Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model (Hu et al, 2025)
[9] MinT: RL Infrastructure for Experiential Intelligence (Lu et al, 2026)
Author
Mind Lab
Core Contributors
Vincent Wang, Kieran Liu, Di Zhang, Andrew Chen, Pony Ma
Team
Andrew Chen, Kaijie Chen, Song Cao, Cleon Cheng, Steven Chiang, Kaixuan Fan, Huan Feng, Nolan Ho, Charles Huang, Fancy Kong, Kyrie Lei, Andrew Lei, Alyssa Li, Lucian Li, Ray Li, Theo Li, Logan Liu, Kieran Liu, Xiang Liu, Irvine Lu, Runze Lv, Pony Ma, Vincent Wang, Rio Yang, Shiro Yang, Maxwell Yao, Regis Ye, Salmon Zhan, Anya Zhang, Di Zhang, Ruijia Zhang, Sueky Zhang, Adrian Zhou, Xinyue Zhu, Murphy Zhuang and Mindverse Team
Names are listed alphabetically within team and acknowledgement.
Citation
Please cite this work using the BibTeX citation:
@misc{wang2026loraoptimalrank, author = {Vincent Wang and Kieran Liu and Di Zhang and Andrew Chen and Pony Ma and {Mind Lab}}, title = {0.03 Parameters, 100 Potential: Reflexivity of Compute Optimal Rank Scaling}, year = {2026}, howpublished = {Mind Lab: A Lab for Experiential Intelligence}, note = {https://macaron.im/mindlab/research/003-parameters-100-potential-reflexivity-of-compute-optimal-rank-scaling} }