How We Build Trillion Parameter Reasoning RL with 10% GPUs
Overview
We present what we believe is the first end-to-end Reinforcement Learning (RL) with Low-Rank Adaptor (LoRA) on a trillion-parameter reasoning model. Our system runs on large Mixture-of-Experts (MoE) models with 10% GPUs compared to conventional full-parameter RL. Our solutions have also been contributed to major open-source projects: NVIDIA’s Megatron-Bridge and Volcengine’s verl.
This post has two main claims:
-
Practical LoRA RL at Trillion-Parameter Scale.
We detail the failure modes inherent to LoRA training on trillion-parameter MoE architectures and demonstrate how our hybrid-parallel engine, integrating verl and Megatron-Bridge, resolves these issues to enable stable and efficient RL.
-
Why RL on Trillion-Parameter Models Pays Off.
We prove that under similar compute budgets, LoRA RL on a trillion-parameter model outperforms full-parameter RL on much smaller models. In other words, when you already have a strong prior, spending RL compute on the largest model could be more effective.
1. Efficient RL on Trillion-Parameter Reasoning Models
Recent months have seen the emergence of trillion-parameter reasoning models such as Kimi-K2 [1] and Ring-1T [2]. These models already reach or surpass frontier closed-source systems on multiple reasoning benchmarks, and their scale is consistent with Chinchilla-style scaling laws [3]: on the order of 1T parameters for roughly 21.2T tokens of pretraining.
However, pretraining alone is not enough. To align these models with concrete downstream agent tasks, we still need RL:
- RL can optimize multi-step reasoning instead of only next-token prediction.
- RL can incorporate task-specific feedback from tools, environments, and humans.
- RL can shape behavior over long horizons, which is increasingly important for agentic systems.
The problem is cost. Running full-parameter RL on a trillion-parameter model is out of reach for most teams, even if they have access to the base checkpoints. The central question is:
Can we make RL on trillion-parameter reasoning models practical at a much lower cost, without sacrificing performance?
Our answer is to combine parameter-efficient LoRA with a hybrid colocated system tailored to trillion-parameter MoE models, largely reducing the RL compute requirement while maintaining performance comparable to full-parameter training.
2. Training Results on Trillion-Parameter Model
We applied our system to RL on Kimi K2 for a set of long-horizon reasoning and agent tasks.
Setup
- Base model: Kimi K2, a trillion-parameter MoE reasoning model.
- Activated / Total parameters: 32.6B / 1.04T
- Activated / Shared / Total experts: 8 / 1 / 384
- Attention Heads: 64
- Adaptation: LoRA on selected dense and expert layers.
- RL algorithm: GRPO-style on-policy optimization with reward models focused on reasoning quality.
- Parallel configuration: hybrid tensor / pipeline / expert / sequence parallelism with LoRA sharding.
- Compute recourse: 8 nodes × 8× NVIDIA H800 (80GB) GPUs (64 GPUs total).
Key observations
- Cost reduction. LoRA RL on Kimi K2 requires about 10% GPUs compared to conventional full-parameter RL.
- Stable learning curves. Training curves show smooth improvement in reward and task success rates over steps, with no catastrophic divergence.
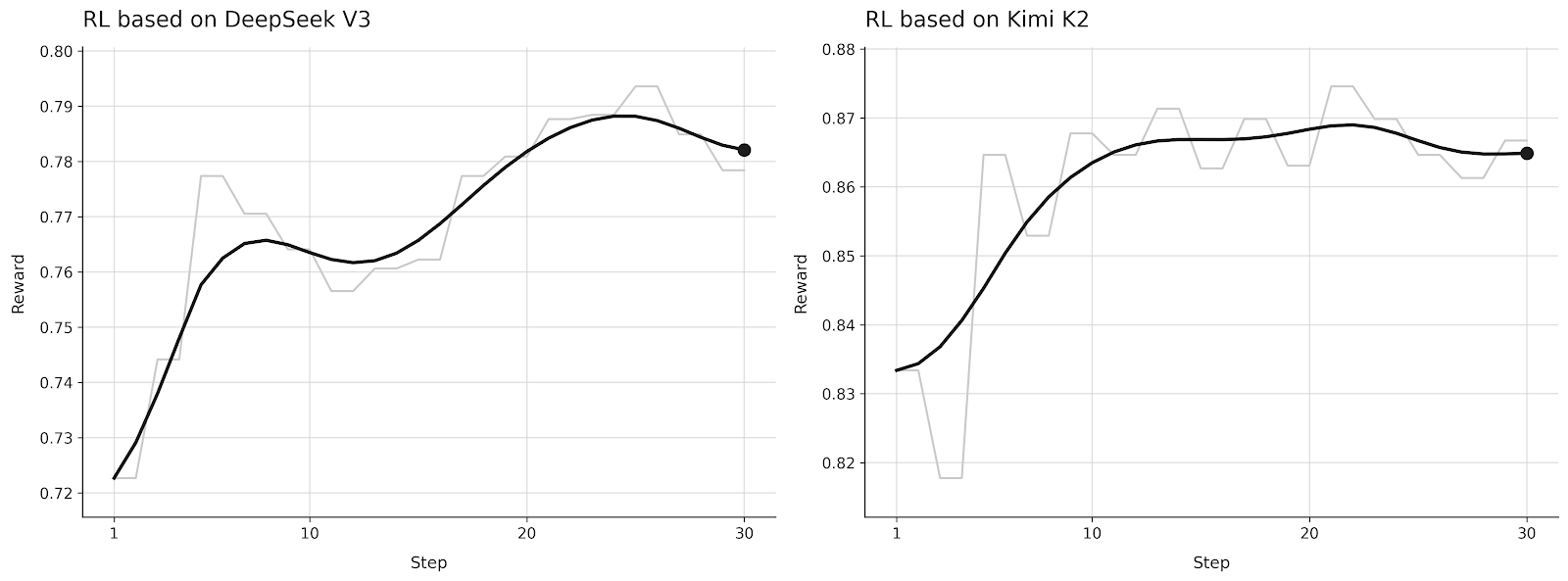
- Preserved generality. Downstream evaluation on held-out benchmarks indicates that LoRA RL preserves the general capabilities of the base model while improving task-specific behavior.
These results demonstrate that trillion-parameter LoRA RL is not only possible, but practical, if the system is designed around MoE parallelism from the start.
3. LoRA RL at Trillion-Scale MoE: Motivation and Failure Modes
3.1 Why LoRA for Trillion-Parameter MoE RL
LoRA [4] is a natural candidate for cost-efficient RL: it keeps the base checkpoint frozen and updates only a small set of low‑rank adapters, so many RL runs can share the same prior. Extending this to trillion‑parameter MoE reasoning models is especially attractive because
- The base model prior is extremely strong.
- Many downstream tasks require behavioral adaptation, rather than wholesale re-learning.
- LoRA can reduce memory and communication costs by an order of magnitude.
However, applying RL with LoRA to trillion-parameter MoE models is not a simple scaling exercise. It introduces new challenges that are absent at smaller scales.
3.2 MoE architecture and parallelism challenges
Modern trillion-parameter reasoning models are Mixture-of-Experts (MoE) Transformers, combining hundreds of experts, heavy all-to-all traffic, and a mixture of dense and expert-specific parameters.
In this setting, a naive data parallel + LoRA approach breaks down for three reasons:
- Routing imbalance: At hundreds-of-experts scale, token routing becomes highly skewed, degrading throughput and amplifying variance in RL updates.
- Communication pressure: Integrating LoRA requires frequent cross-device collection of adapter weights, which introduces substantial all-gather overhead and can trigger OOM.
- Complex parallel layouts: Simple layouts fail to keep GPUs utilized when rollouts and training must be tightly coupled on the same hardware.
To make RL feasible at this scale, tensor [5,6], pipeline [7], expert [8], and sequence parallelism [9] must work in concert while remaining compatible with LoRA on both dense and expert submodules.
3.3 Training–inference mismatch at RL scale
In realistic RL setups, rollouts and training usually use different backends:
- Inference may run on a concurrent, independent engine optimized for serving.
- Training may run under a heavy, fully sharded backend requiring timely synchronizing.
This leads to a distribution mismatch between the policy that generates trajectories and the policy that is updated. At trillion-parameter scale, this mismatch is amplified:
- Even small changes in logits can cause large differences in sampled trajectories.
- Naive importance sampling ratios can explode and destabilize RL.
A stable solution must explicitly correct for this mismatch without creating unacceptable variance.
4. Our Approach: Hybrid Colocated Parallel LoRA RL on Kimi-K2
To address these challenges, we built a hybrid colocated parallel LoRA RL engine for trillion-parameter MoE reasoning models and validated it on Kimi-K2.
4.1 Hybrid parallel design
We use a unified parallelism strategy:
- Tensor parallelism for large matrix multiplications in same node. (tp_size<=8 to avoid communication between nodes)
- Pipeline parallelism to spread layers across nodes.
- Expert parallelism to shard MoE experts and route tokens across devices.
- Sequence parallelism where needed for long contexts.
- Conventional data parallelism & tenser parallelism for inference engines.
The key design principle is to treat parallelism as a resource to be scheduled, not a fixed layout. This allows us to:
- Maintain high GPU utilization during both rollout and training.
- Keep LoRA updates local to each shard to reduce communication.
- Preserve MoE routing behavior while updating only a small fraction of parameters.
4.2 LoRA design for 10% GPU requirement
Our LoRA configuration for Kimi K2 follows three rules:
- Attach adapters to both dense and expert layers where they have the highest leverage on reasoning behavior.
- Use a moderate LoRA rank (e.g., rank = 128 [10]) that balances expressivity and stability at MoE scale.
- Keep adapters fully sharded and fused with existing kernels where possible, to avoid additional overhead.
This yields a LoRA parameter count and communication volume that are roughly 10% of full-parameter RL on the same model, while still allowing the RL signal to influence both global and expert-specific behavior.
4.3 Implementation:
verl + Megatron-Bridge
To make the system usable, we integrated our design into an open training stack:
- verl provides the RL training loop, rollout orchestration, and reward aggregation.
- Megatron-Bridge connects verl to a Megatron-style MoE backend, exposing tensor, pipeline, expert, and sequence parallelism in a unified interface.
We contributed patches to:
-
Enable LoRA RL on MoE experts at trillion-parameter scale.
-
Support hybrid parallel layouts that remain compatible with RL rollouts.
-
Implement truncated importance sampling ratios that correct training–inference mismatch without causing divergence.
Using this stack, we obtained stable, efficient RL training on Kimi K2 with LoRA.
https://github.com/volcengine/verl/pull/4063
https://github.com/modelscope/ms-swift/pull/6714
https://github.com/modelscope/ms-swift/pull/6720
https://github.com/NVIDIA-NeMo/Megatron-Bridge/pull/1310
https://github.com/NVIDIA-NeMo/Megatron-Bridge/pull/1380
Other key points
- We built a hybrid colocated parallel training infra to support 1T-parameter MoE-LoRA.
- We implemented HTTP-endpoint inference backend integration for hybrid rollout engines (serve-optimized inference with training-optimized sharded updates).
- We added sharded LoRA utils to support distributed save & load & merge & quantize, while naive CPU operation takes hours and single-GPU LoRA handling OOMs at 1T scale.
5. Why RL on Trillion-Parameter Models Beats RL on Small Models
A natural objection is:
Why spend RL compute on a trillion-parameter model at all? Would it not be cheaper to train a smaller model with full-parameter RL?
To address this, we ran a controlled comparison.
5.1 Experimental design
We study how base model size affects RL efficiency under similar RL compute, using three policies trained with RL:
- DeepSeek-Distill-Qwen-1.5B (full-parameter RL; 1.5B trainable parameters)
- DeepSeek-Distill-Qwen-7B (LoRA, rank 64; 0.16B trainable parameters)
- DeepSeek-Distill-Qwen-32B (LoRA, rank 8; 0.07B trainable parameters)
All models are trained only on DAPO-Math-17k and evaluated on AIME 2025 (in-domain) and GPQA Diamond (out-of-domain).
We match:
- Number of environment interactions
- Total RL FLOPs (tokens × parameters × updates)
- Reward models and RL pipeline
To remove the trivial advantage that larger models start from higher absolute scores, we report a headroom-normalized Δ metric: improvement relative to the remaining headroom between the initial score and the maximum attainable score.
5.2 Results
We observe a consistent pattern:
- Larger base models with LoRA achieve larger headroom-normalized gains than the 1.5B full-parameter model, despite using far fewer trainable parameters.
- RL trained on math transfers well to GPQA Diamond, with the strongest gains for 32B + LoRA, indicating that a stronger prior yields better out-of-domain generalization.
Overall, under a similar RL compute budget, “large prior + small LoRA” is more effective and efficient than full-parameter RL on a small model.
Experiment results of different base-model sizes under comparable trainable scale
| Model | Trainable parameters | AIME 2025 (before/after) | Headroom-normalized Δ metric | GPQA Diamond (before/after) | Headroom-normalized Δ metric |
|---|---|---|---|---|---|
| DS-Distill-Qwen-1.5B Full | 1.5B | 18.75 / 25.52 | 8.33% | 16.24 / 37.18 | 25.00% |
| DS-Distill-Qwen-7B LoRA, r=64 | 0.16B | 29.06 / 37.08 | 11.31% | 34.26 / 52.16 | 27.23% |
| DS-Distill-Qwen-32B LoRA, r=8 | 0.07B | 31.77 / 45.83 | 20.61% | 45.43 / 63.45 | 33.02% |
5.3 Interpretation: RL is prior-limited
These results support a simple hypothesis:
- RL is prior-limited. If the base model cannot produce high-quality trajectories, RL has little useful signal to amplify.
- Larger models provide a much stronger prior. They already encode rich patterns in reasoning, tool use, and human interaction, so RL can refine these behaviors instead of reinventing them.
Under a fixed RL compute budget, it is therefore more efficient to run LoRA RL on the strongest available model than to run full-parameter RL on a weaker one. This is the core motivation for investing in trillion-parameter LoRA RL, rather than treating RL as a separate “small-model training” problem.
6. What Comes Next
This work is our first step on infra for trillion-parameter reasoning RL. We are actively extending it in several directions.
- Adaptive Hybrid Scheduler Automatically reconfigures tensor, pipeline, expert, and sequence parallelism based on live metrics such as utilization, memory, and step time. The goal is to make trillion-parameter RL efficient without manual tuning.
- Reasoning Distillation Uses the trillion-parameter LoRA-trained model as a teacher for smaller adapter-only students, preserving reasoning quality while lowering serving cost.
- Unified Efficiency Benchmark Defines standardized metrics for RL on large reasoning models, including tokens, experts, latency, and energy, so that different RL algorithms and LoRA designs can be compared fairly.
Our long-term goal is to make reasoning-level intelligence at trillion-parameter scale not only possible, but also scalable, efficient, and affordable for anyone who wants to build real agentic systems.
References
[1] Kimi K2: Open Agentic Intelligence (Team Kimi et al, 2025)
[2] Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model (Team Ling et al, 2025)
[3] Training Compute-Optimal Large Language Models (Hoffmann et al, 2022)
[4] LoRA: Low-Rank Adaptation of Large Language Models (Hu et al, 2022)
[5] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism (Shoeybi et al, 2019)
[6] Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM (Narayanan et al, 2021)
[7] PipeDream: Fast and Efficient Pipeline Parallel DNN Training (Harlap et al, 2018)
[8] DeepEP: an efficient expert-parallel communication library (Zhao et al, 2025)
[9] Sequence Parallelism: Long Sequence Training from System Perspective (Li et al, 2023)
[10] LoRA Without Regret (Schulman et al, 2025)
Author
Mind Lab
Core Contributors
Kieran Liu, Steven Chiang, Rio Yang, Alex Yin, Pony Ma, Andrew Chen
Team
Andrew Chen, Kaijie Chen, Steven Chiang, Yuhua Jiang, Andrew Lei, Guanming Liu, Kieran Liu, Scott Liu, Irvine Lu, Pony Ma, Alex Yin, Rio Yang and Mindverse Team
Acknowledgement
Special thanks to Shunyu Yao for their valuable feedback on this blog.
Names are listed alphabetically within team and acknowledgement.
Citation
Please cite this work using the BibTeX citation:
@misc{liu2025Build, author = {Kieran Liu and Steven Chiang and Rio Yang and Alex Yin and Pony Ma and Andrew Chen and {Mind Lab}}, title = {Building trillion-parameter reasoning RL with 10\% GPUs}, year = {2025}, howpublished = {Mind Lab: A Lab for Experiential Intelligence}, note = {https://macaron.im/mindlab/research/building-trillion-parameter-reasoning-rl-with-10-gpus} }