From Words to Worlds: How World Models Unlock Scalable Agentic RL
The Experience Bottleneck in Agentic RL
Agentic reinforcement learning is hitting a wall—but not the one you might expect.
Over the past year, we have seen remarkable progress in RL for agents: models that browse the web, write and execute code, and interact with complex tool ecosystems. But as these systems improve, a new bottleneck emerges. Unlike static pretraining corpora, experience must be collected through interaction. Real environments are slow, expensive, non-adaptive, and fundamentally limited in coverage.
This is what we call the experience bottleneck: the growing gap between the experience agents need and the experience the world can provide.
At Mind Lab, we believe that closing this gap requires rethinking how agents learn from experience. One promising direction is world modeling—training models to simulate environment dynamics so that agents can learn from imagined interaction, not just real episodes. This paradigm has already shown remarkable success in visual domains, where learned world models enable agents to master diverse control tasks through imagination [1].
This raises a natural question:
Can large language models serve as effective world models for agentic learning? And if so, under what conditions do they actually help?
Our latest research provides systematic answers to these questions.
Text Environments as a Unifying Testbed
To study LLMs as world models in a controlled setting, we focus on text-based environments. This abstraction preserves the core challenges of agent-environment interaction—state tracking, action execution, reward prediction—while reframing the objective from next-token prediction to next-state prediction.
Formally, we model the interaction between an agent and a world model as a multi-turn language-based decision process.
Agent. A text-based agent operates in a ReAct-style [2] loop, producing reasoning traces and actions:
where is the textual observation at step , is the agent's internal reasoning trace, and is the action.
World Model. The world model predicts the next state and reward given the interaction history:
where is the predicted next state and is a binary reward indicating task success or termination.
Interactive Process. Together, agent and world model form an iterative loop:
which unrolls into a multi-turn trajectory in the world model , compared against the real-environment trajectory to evaluate fidelity.
Through this lens, world modeling becomes multi-turn next-state prediction under interaction.
We study five representative environments spanning both structured and open-ended dynamics:
| Environment | Domain | Dynamics |
|---|---|---|
| ALFWorld [3] | Household tasks | Structured, embodied |
| SciWorld [4] | Science experiments | Structured, causal |
| TextWorld [5] | Interactive fiction | Structured, narrative |
| WebShop [6] | Web navigation | Open-ended, compositional |
| StableToolBench [7] | API tool use | Open-ended, symbolic |
Together, these settings provide a comprehensive testbed for evaluating language models as text-based world simulators.
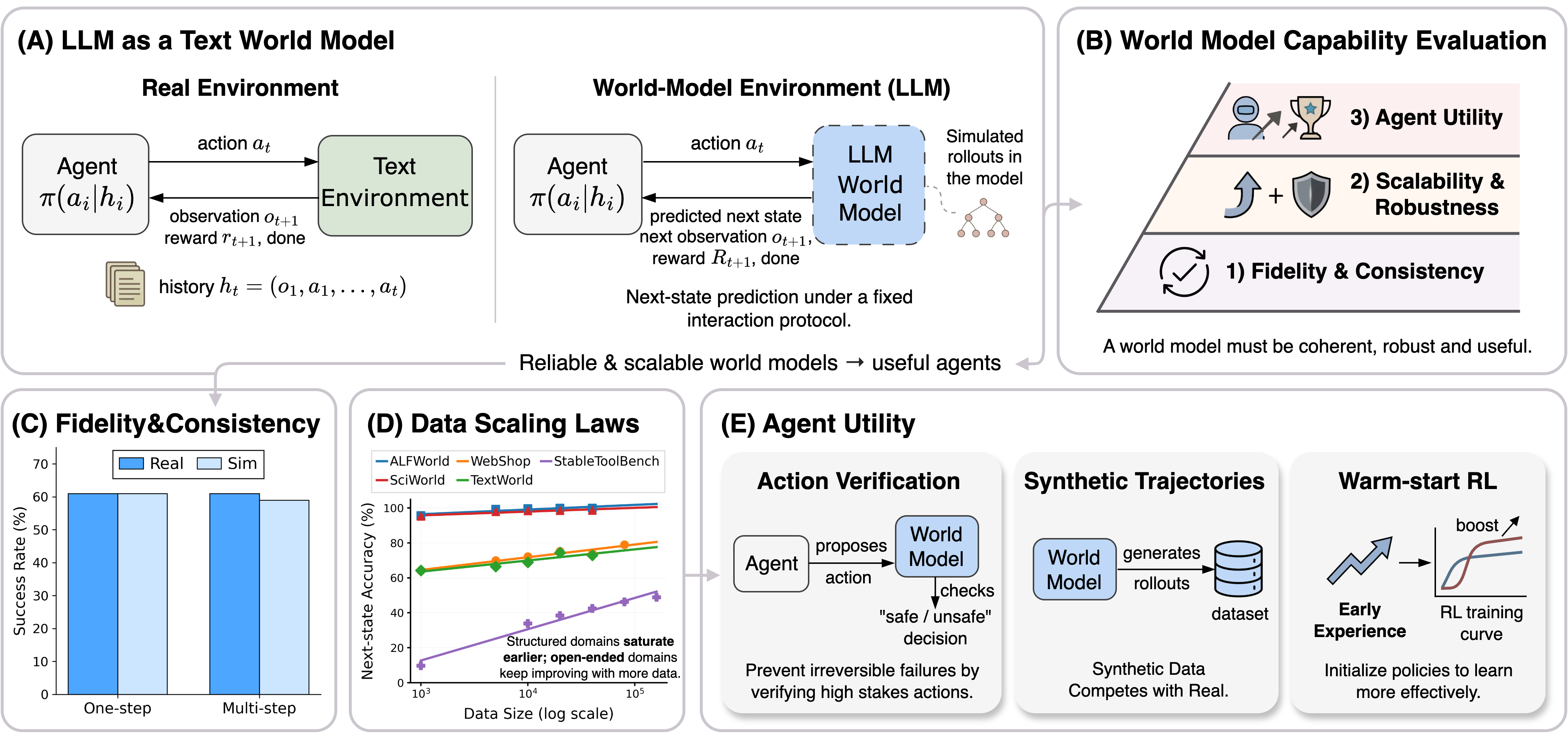
Figure 1: LLMs as text-based world models for agent learning. (A) We formulate world modeling as next-state prediction under a fixed text-based interaction protocol. (B) Assess world-model capability along three axes: fidelity/consistency, scalability/robustness, and agent utility. (C) World model exhibits high fidelity and consistency in both single-step predictions and long-horizon rollouts. (D) Performance scales predictably with increased training data across text environments. (E) Faithful world models enhance agents via verification, synthetic data generation, and improved reinforcement learning through stronger initialization.
A Three-Level Evaluation Framework
Evaluating world models for agent learning requires more than just prediction accuracy. We introduce a three-level framework that captures the full spectrum of capabilities:
- Fidelity & Consistency: Does the world model maintain coherent latent states over short and long horizons?
- Scalability & Robustness: How do world modeling capabilities scale with data and model size? Do they generalize under distribution shift?
- Agent Utility: Do high-fidelity world models translate into measurable improvements for downstream agents?
This framework moves beyond prior work that focused primarily on one-step prediction accuracy, explicitly modeling and evaluating long-horizon consistency—which is critical for applications like synthetic data generation and model-based RL.
Evaluation Metrics
We evaluate world models along two dimensions:
Fidelity (One-step Prediction Accuracy). Given a real trajectory prefix, we measure whether the world model correctly predicts the next state. Formally, we compute Exact Match (EM) accuracy:
where is the model's prediction and is the ground-truth next state and reward.
Consistency (Long-horizon Transfer). For multi-step rollouts, we define the Consistency Ratio (CR):
where Real is the agent's success rate in the real environment, and W2R (World-to-Real) is the success rate when replaying world-model-generated actions in the real environment. A CR close to 1.0 indicates that trajectories generated in simulation remain executable in reality.
Key Findings
1. LLMs Exhibit Internal Latent Dynamics
We find that pretrained LLMs already encode meaningful world knowledge. Models like Claude and Gemini achieve strong next-state prediction in structured environments with only a few in-context examples. On SciWorld, Claude's accuracy jumps from 56.8% to 73.1% with just three demonstrations.
However, this implicit knowledge has limits. In open-ended environments like WebShop, few-shot prompting plateaus around mid-50s, indicating that prompting alone cannot capture the full diversity of transition patterns.
Supervised fine-tuning changes the picture dramatically. Open-source 7B models trained on transition trajectories achieve 99% accuracy on ALFWorld and 98% on SciWorld. The takeaway: high-fidelity world modeling requires dynamics-aligned training.
| Model | Setting | ALFWorld | SciWorld | TextWorld | WebShop |
|---|---|---|---|---|---|
| Claude-sonnet-4.5 | Zero-shot | 64.7 | 56.8 | 17.7 | 58.8 |
| Claude-sonnet-4.5 | Few-shot (3) | 77.0 | 73.1 | 49.1 | 56.7 |
| Gemini-2.5-flash | Few-shot (3) | 61.9 | 61.2 | 40.4 | 66.1 |
| Qwen2.5-7B | SFT | 99.9 | 98.6 | 70.6 | 79.1 |
| Llama3.1-8B | SFT | 99.7 | 98.6 | 70.5 | 77.2 |
Table 1: Next-state prediction accuracy (%) across different settings. SFT models dramatically outperform even the best few-shot prompted frontier models.
2. World Models Maintain Long-Horizon Consistency
A reliable world model must not only predict the next state accurately, but maintain coherence over extended rollouts. We measure this through the Consistency Ratio (CR) defined above.
In structured environments, fine-tuned world models achieve —meaning multi-step trajectories generated in simulation remain executable when transferred to reality.
| Agent | ALFWorld CR | SciWorld CR | TextWorld CR | WebShop CR |
|---|---|---|---|---|
| GPT-4o | 0.99 | 0.90 | 0.98 | 0.56 |
| GPT-4.1 | 1.04 | 1.07 | 1.00 | 0.58 |
| GPT-5 | 0.95 | 0.89 | 1.00 | 0.61 |
| Claude-sonnet-4.5 | 0.93 | 0.88 | 1.00 | 0.82 |
| Average | 0.96 | 0.91 | 0.92 | 0.67 |
Table 2: Consistency Ratio (CR = W2R/Real) across environments using Qwen2.5-7B world model. Values ≥ 1.0 indicate world-model rollouts transfer perfectly (or better) to the real environment.
Open-ended environments are harder. WebShop shows consistency around 56–67%, primarily due to diverse search results the model struggles to simulate. But when we anchor rollouts with real observations (e.g., actual search results), consistency jumps to nearly 100%. This suggests that partial real-world grounding can effectively reduce simulation drift.
3. Scaling Laws for World Models
One of our most important findings is that world modeling follows predictable scaling laws—but with strong environment dependence.

Figure 2: Next-state prediction accuracy under varying training data sizes. Structured environments saturate with modest data (~20K trajectories), whereas open-ended environments continue to benefit from larger datasets.
Data scaling: Structured environments improve rapidly and saturate around 20K trajectories, consistent with their low-entropy dynamics. Open-ended environments scale more gradually—WebShop benefits up to 70K trajectories, while StableToolBench shows no saturation at 160K samples.
Model scaling: In structured environments, 1.5B models already capture core dynamics. In open-ended environments, larger models offer steady accuracy gains, suggesting that success requires both extensive data and sufficient capacity.

Figure 3: Next-state prediction accuracy across the Qwen2.5 model family. Smaller models capture structured dynamics effectively, whereas complex settings benefit markedly from increased model capacity.
4. Generalization Beyond Memorized Configurations
A central concern in world model design is whether models simply memorize specific configurations. We test this through out-of-distribution evaluation in ALFWorld, varying room layouts and introducing entirely new room types.

Figure 4: Task success rate (%) in ALFWorld under different OOD settings. World models maintain strong performance even when layouts or room types change, indicating they capture transferable dynamics rather than memorizing specific configurations.
The results are encouraging: world models maintain success rates closely aligned with the real environment across both OOD settings. This indicates that LLM world models capture transferable transition dynamics rather than memorizing specific layouts.
We also find that cross-environment training provides stable positive gains. A single world model trained on multiple environments can robustly serve all of them, with particularly strong improvements in TextWorld and WebShop through shared physical and narrative dynamics.

Figure 5: Next-state prediction accuracy under mixed vs. separate training (1K samples per environment). Mixed training consistently accelerates learning and improves final accuracy across most environments.
5. World Models Provide Real Agent Utility
The ultimate test of a world model is whether it helps agents learn better. We demonstrate three concrete applications:
Pre-execution verification. In WebShop, where checkout is irreversible, we use the world model as a lightweight verifier. Before committing, the agent simulates the outcome and only executes when the prediction indicates success. This simple strategy improves success rates across all agents, with the largest gains for medium-capacity models.

Figure 6: Pre-execution verification workflow. The world model simulates irreversible actions (e.g., checkout) before execution, allowing agents to avoid costly mistakes by only committing when the prediction indicates success.
Synthetic data generation. When real interaction is expensive, world models can synthesize training trajectories. We find that world-model-generated trajectories are highly competitive with real data. In SciWorld, synthetic data matches real data performance, while mixing both sources outperforms either alone.

Figure 7: Task success rate of agents trained on different data sources. World-model-generated trajectories are competitive with real data, and mixed regimes yield the most stable gains.
Early experience for RL. Exposing agents to environment dynamics before policy learning provides a useful inductive bias [8]. Our WM-SFT → Agent-SFT → RL pipeline delivers consistent gains on both ALFWorld and SciWorld, stabilizing RL training and yielding higher final success rates.

Figure 8: Task success rate of RL-trained agents with and without early world-model experience. Pre-training on environment dynamics stabilizes learning and improves final performance.
Why This Matters: From World Models to Minds
At Mind Lab, we are building systems that learn from real-world experience. But real experience is fundamentally limited—slow, costly, and incomplete. World models offer a path through this bottleneck.
The key insight from this work is that LLMs are not just sequence predictors; they are learnable simulators of interactive worlds. This reframing unlocks capabilities that go far beyond data augmentation:
| Capability | What World Models Enable |
|---|---|
| Reasoning | Prediction is the core of reasoning. World models provide the substrate for causal inference, counterfactual thinking, and planning. |
| Adaptation | World models can be queried, rewound, and explored—an internal playground where agents adapt before facing real consequences. |
| Efficiency | Agents learn from imagined experience, reducing reliance on costly real interactions. |
| Safety | Simulating irreversible actions before execution turns high-stakes decisions into low-risk explorations. |
In our introductory blog, we argued that a mind maintains and updates internal models of the world. A system with a faithful world model can form expectations, detect surprises, plan ahead, and learn from imagination—precisely the capabilities that distinguish a mind from a brain.
Of course, these gains depend on behavioral coverage, distributional alignment, and environment complexity. Our work delineates when world modeling helps—and where it falls short.
Looking Ahead
This research establishes an empirical foundation for treating LLMs as general-purpose world models. But text is only the beginning. We are extending these ideas to multimodal and embodied domains, where the experience bottleneck is even more severe.
From words to worlds. From static models to adaptive minds. This is the direction we're building toward at Mind Lab.
References
[1] Mastering Diverse Domains through World Models, (Hafner et al, 2023)
[2] ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al, 2023)
[3] ALFWorld: Aligning Text and Embodied Environments for Interactive Learning (Shridhar et al, 2021)
[4] ScienceWorld: Is your Agent Smarter than a 5th Grader? (Wang et al, 2022)
[5] TextWorld: A Learning Environment for Text-based Games (Côté et al, 2018)
[6] WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents (Yao et al, 2022)
[7] StableToolBench: A Stable Large-Scale Benchmark for Tool Learning (Guo et al, 2024)
[8] Agent Learning with Early Experience (Zhang et al, 2025)
Author
Yixia Li, Hongru Wang, Jiahao Qiu, Zhenfei Yin, Dongdong Zhang, Cheng Qian, Zeping Li, Pony Ma, Guanhua Chen, Heng Ji, Mengdi Wang
Acknowledgement
This work was completed by Yixia Li under the guidance of our guest scientists, Hongru Wang (University of Edinburgh) and Guanhua Chen (SUSTech). Mind Lab also contributed, working with researchers from Princeton University, UIUC, Microsoft Research Asia, Oxford University, and Fudan University.
Citation
Please cite this work using the BibTeX citation:
@article{li2025wordtoworld, title = {From Word to World: Can Large Language Models be Implicit Text-based World Models?}, author = {Yixia Li and Hongru Wang and Jiahao Qiu and Zhenfei Yin and Dongdong Zhang and Cheng Qian and Zeping Li and Pony Ma and Guanhua Chen and Heng Ji and Mengdi Wang}, journal = {https://arxiv.org/abs/2512.18832}, year = {2025} }
or cite this blog as:
@misc{mindlab2025wordtoworlds, author = {Yixia Li and Hongru Wang and Pony Ma and Guanhua Chen and Mind Lab}, title = {From Words to Worlds: How World Models Unlock Scalable Agentic RL}, year = {2025}, howpublished = {Mind Lab: A Lab for Experiential Intelligence}, url = {https://macaron.im/mindlab/research//how-world-models-unlock-scalable-agentic-rl} }