Router Replay R3: Why It Failed and How We Fixed It
Training-inference mismatch (TIM) is the silent failure mode for MoE: the training path and the inference path diverge, gradients stop matching the policy you deploy, and optimization drifts. In this blog post, we walk through a real case where TIM is much worse on a DeepSeekV3-architecture model (Moonlight-16B-A3B) than on Qwen3 MoE models (Qwen3-30B-A3B). We investigate why common mitigations failed, and how we fixed Router Replay R3 across vLLM and veRL to remove the mismatch without discarding samples.
TL;DR
- TIM is significantly worse on DeepSeekV3-style MoE (Moonlight-16B-A3B) than on Qwen3 MoE (Qwen3-30B-A3B).
- Rollout correction in veRL reduces observed TIM but does so by clipping samples, eventually discarding everything and halting training.
- Existing Router Replay R2 did not improve TIM in our setup, and R3 is broken in veRL and vLLM for DeepSeekV3-style MoE.
- After fixing R3 in vLLM + veRL, R3 alone (no rollout correction) has already reduced TIM substantially without shrinking the effective sample set.
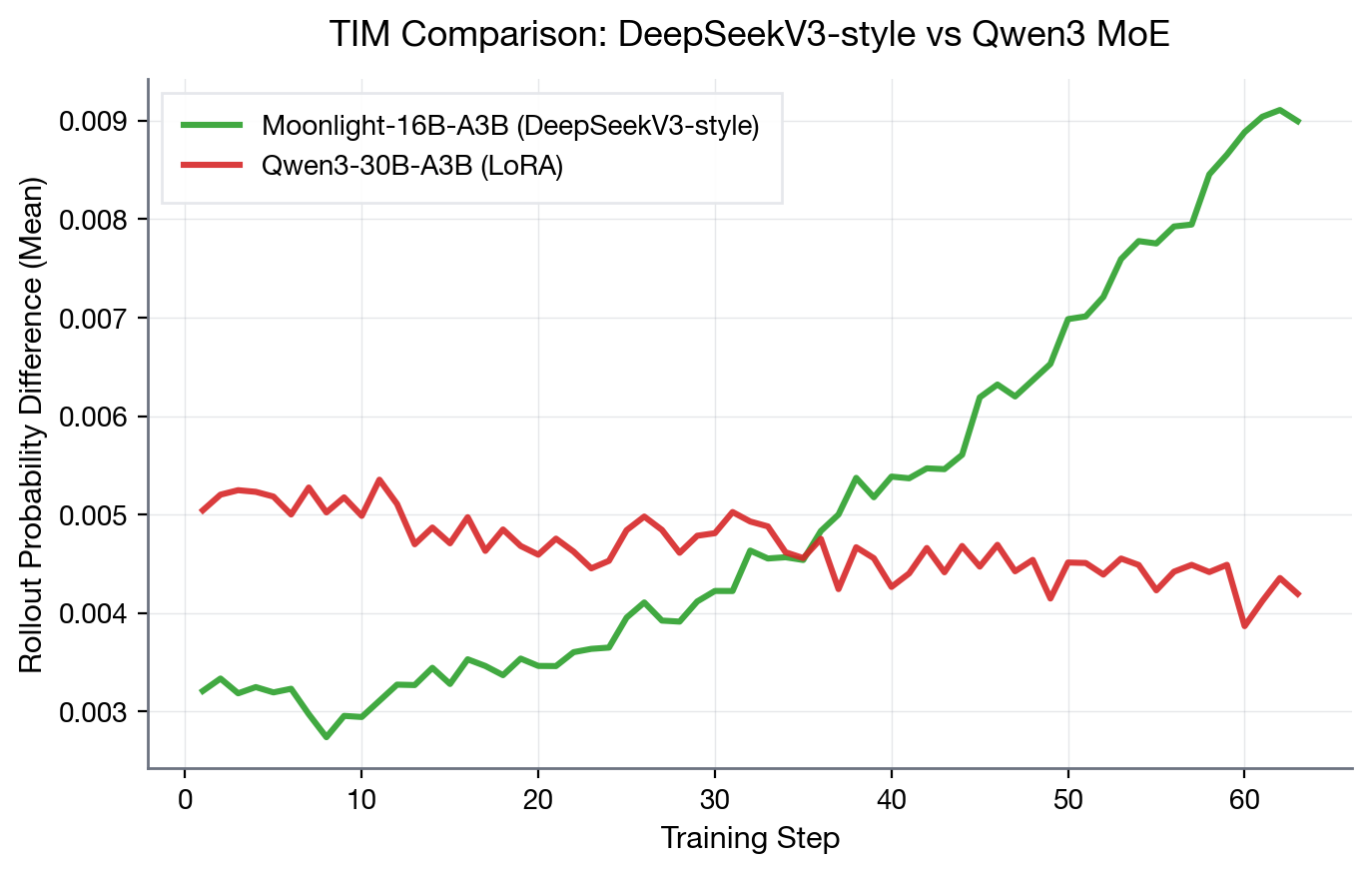
Figure 1: TIM comparison between Moonlight-16B-A3B (DeepSeekV3-style) and Qwen3-30B-A3B. The DeepSeekV3-style architecture shows significantly higher training-inference mismatch. Note: Qwen3-30B-A3B data is LoRA-based.
Background
Training-inference mismatch (TIM) is a foundational stability challenge in modern reinforcement learning systems for large language models. At a high level, TIM emerges when the policies computed during training diverge from those computed during inference deployment, causing gradient-based optimization to target trajectories the model will never follow in production.
In dense models, TIM manifests as numerical inconsistencies, small rounding errors or precision loss that accumulate across a training step. But in Mixture-of-Experts (MoE) models, TIM is dramatically amplified because the routing mechanism (which expert to activate for each token) is discrete and highly sensitive to small perturbations. When routing decisions differ between training and inference, tokens pass through different experts, producing fundamentally different activations and gradients. This amplification effect explains why MoE models are significantly more prone to RL training instability and collapse than their dense counterparts.
The field has developed various approaches to address TIM [1], each tackling different layers of the problem:
Root-Cause Approaches (Exact Bitwise Consistency)
Recent works (SGLang + Slime FSDP [2], as well as vLLM + TorchTitan [3]) achieve exact numerical matching between inference and training by ensuring batch invariance [4], identical kernels, and matched backward passes. This achieves KL=0.0 between engines but incurs performance penalty. In addition, FSDP style training engines are very inefficient for MoE models, achieving exact numerical matching between Megatron and inference engines requires extensive engineering effort.
Symptom-Management Approaches (Work Within Mismatch Tolerance)
Algorithmic Corrections via Importance Sampling
Methods like Token-level Truncated Importance Sampling (TIS) [5] and Masked Importance Sampling (MIS) [6] attempt to correct biased gradients by reweighting samples based on the ratio of training vs. inference probabilities. However, these corrections suffer from high variance and eventually collapse when cumulative mismatch is large and keeps growing, as they treat the symptom (divergent gradients) rather than the root cause (divergent routings).
Sample Clipping & Filtering (Discard Divergent Data)
Rollout correction can also clip or discard samples whose rollout trajectory is too far from the training distribution. GSPO (Group Sequence Policy Optimization) [7] refines this using geometric mean ratios and length normalization for more stable clipping. FSPO (Fair Sequence Policy Optimization) [8] further improves by enforcing length fairness in the clipping band. However, all these approaches reduce the effective training dataset size. In the worst case as observed, TIM can grow faster than clipping can discard samples, eventually halting training.
MoE-Specific Routing Solutions (Address Routing as Main Cause)
Router Replay R2 (Training-Side Routing Consistency) [7]
Records routing decisions within the training engine (Megatron) and replays them on subsequent micro-batches. This is local and deterministic but does not address the inference-training routing gap, so TIM can still persist.
Router Replay R3 (Rollout-Training Routing Alignment) [9]
Records routing distributions from the inference engine (vLLM) during rollout and replays them in the training engine (Megatron). Theoretically, R3 directly targets the root cause in MoE: if routing decisions match, the experts produce identical activations, and gradients no longer diverge from deployed behavior. This approach preserves all training data (no clipping or masking) because it eliminates the mismatch rather than filtering around it.
Why DeepSeekV3-Style MoE Looks Worse than Qwen3 MoE
We observed a much larger TIM on Moonlight-16B-A3B than on Qwen3-30B-A3B. The architectural differences amplify sensitivity significantly:
DeepSeek-V3-style MoE [10] employs a hybrid architecture with the first or more layers as dense FFN blocks before switching to MoE layers. Additionally, DeepSeek-V3-style routing incorporates grouped top-k selection combined with sigmoid-based affinity scoring. While this approach adds nuanced semantics to expert selection beyond standard top-k softmax routing, it also introduces extra sensitivity to implementation details and precision variations.
Qwen3 MoE [11] primarily uses traditional softmax-based top-k routing with auxiliary loss for balancing. The simpler routing logic is more robust to implementation differences, and the uniform application across all layers reduces indexing complexity.
Experiments with veRL + vLLM + Megatron
We used veRL for training, vLLM for rollout, and Megatron as the training backend, using Moonlight-16B-A3B as a quick validation prototype for DeepSeekV3-architecture MoE. The training is done on dapo-math-17k using DAPO.
In our setup, R2 did not improve TIM. However, before our fix, R3 breaks the training entirely because the captured replay data was missing and misaligned, leading to the initial rollout probs diff mean value 0.7826, standard value 0.3086, and pearson correlation value 0.1443. After we implement the fixes for both veRL and vLLM, it works perfectly and resolves the main source of TIM in our case.
Runs compared:
DAPO-Moonlight-16B-A3B-megatron-original: no rollout correction/router replay.DAPO-Moonlight-16B-A3B-megatron-gspo-decoupled_geo_rs_seq_tis: no router replay. We use the most effective rollout correction we identified, which is to use decoupled mode with Geometric Mean RS and Sequence-level Truncated IS (ratio-based), which combines the Geometric Mean Filter (ratio-based validity check) with Clipped Sequence Weight (debiasing), using E[log(r)] (ideal = 0.0). We set the upper threshold for sequence IS weights to be 2.0 and Geometric RS threshold to be (±0.1%), we also use it together with GSPO.DAPO-Moonlight-16B-A3B-megatron-r3: Router replay R3 enabled, no rollout correction.
Results
TIM Metrics: Rollout Probability Mismatch

Figure 2: Maximum rollout probability difference per step. The original and rollout-corrected runs climb rapidly and remain high, while the R3-fixed run stays consistently lower.

Figure 3: Standard deviation of rollout probability difference. R3 maintains lower variance throughout training.

Figure 4: Mean rollout probability difference. R3 shows substantially reduced TIM compared to baselines.
Training Stability Signals

Figure 5: PPO KL divergence. The R3 run maintains near-zero KL divergence (0.000026 at step 46), while other runs increase significantly.

Figure 6: Gradient norm. R3 exhibits the most stable gradients, whereas baselines show higher variance and drift.
Quality

Figure 7: Critic score mean. The R3 run sustains higher scores relative to baselines, which trend downward.

Figure 8: Validation accuracy on the math DAPO task. The R3 run improves monotonically and finishes strongest, while the original and rollout-corrected runs degrade.
Fixing Router Replay R3
Thankfully, before we came to the conclusion that R3 is also not helpful, we did not give it up and found several clues which indicated that this should be related to bugs:
- For R2, it worked as expected (though not effective), but R3 is completely broken. This pointed to a problem in the capture and replay path instead.
- For Moonlight 16B A3B, we found that
router_instances=26,num_layers=27, which indicated the model has 27 layers but only 26 routers (first layer is dense). - vLLM reported non-zero
topk_ids, but the replay tensor arriving in Megatron showedmin_expert=0 max_expert=0, i.e., all zeros.
We proceeded with checking the code logic and eventually implemented fixes. The veRL-related ones have all been merged into the upstream and vLLM-related ones are pending review:
-
Broken capture logic in vLLM: In the latest vLLM code, the routed experts capture logic is broken, as
RoutedExpertsCapturer.create()runs after model construction (during KV-cache init), butFusedMoEonly bindsself.captureininit. The result is that capture never happens and the routed experts buffer remains all zeros.Fix: We bind the capturer on first forward once it exists. This ensures capture works even though the capturer is created after model init.
-
EPLB ID mapping issue: When Expert Parallelism Load Balancer (EPLB) is enabled, vLLM maps logical expert IDs to physical IDs. Megatron expects logical IDs for replay. Capturing post-EPLB IDs breaks replay.
Fix: We first compute routing with
BaseRouter._compute_routing, capture logical IDs, then apply EPLB mapping for execution. Replay now receives the expected logical IDs. -
Dense layer offset corruption: vLLM reports
routed_expertsacross all transformer layers (including dense). Megatron only has routers for MoE layers. Mapping withi + offsetsilently shifts every MoE layer after a dense layer.Fix: When the replay tensor spans the full
num_layers, map using the router's globallayer_numberinstead of local offsets. This prevents the dense-layer shift from corrupting replay. We also patchTopKRouter.set_layer_numberto store the global layer number in eachRouterReplayinstance so global alignment is reliable with VPP/PP. -
AlltoAll split size mismatch: When router replay is enabled, and we have
moe_token_dispatcher_type = "alltoall", duplicate indices in top_indices can causerouting_map.sum() < num_tokens * topk, leading to split size mismatch in alltoall.Fix: We derive it from the routing map instead in this case.
Why This Matters Beyond Fixing the Bugs
Fixing these engineering issues enables Router Replay R3 to work as intended for DeepSeek V3 style models for veRL and vLLM: it aligns routing distributions between inference and training without discarding training data. Unlike sample clipping (which eventually halts training when TIM grows faster than clipping discards) or algorithmic corrections (which add variance and complexity), R3 eliminates the main source of such mismatch.
This positions R3 as a complementary solution in the TIM mitigation landscape:
- For models with numerical precision issues: Use FP16 (simplest, solves class of numerical problems) [12]
- For exact matching requirements: Use the bitwise consistency approach (performance-intensive but perfect)
- For MoE routing-specific instability: Use R3 (target root cause without data loss; works with minor performance overhead)
It's always a good idea to use symptom-management approaches such as importance sampling and clipping as a last resort and an additional guard if none of the above works, as they can make training unstable if TIM keeps growing.
Conclusion
Router Replay R3, when properly implemented, provides a principled solution to the routing-divergence problem in MoE RL. Unlike algorithmic corrections which can reduce training data and eventually halt training, R3 directly aligns the routing decisions between inference and training without data loss.
The key insight is architectural: not all MoE designs have equal sensitivity to TIM. Uniform routing logic (Qwen3) is more robust than hybrid architectures with complex routing semantics (DeepSeekV3). For architectures like DeepSeekV3-style MoE that are particularly sensitive to routing divergence, R3 offers substantial stability gains.
This work demonstrates the importance of careful engineering in RL systems. What appeared to be a fundamental limitation of R3 turned out to be implementation bugs. By fixing these issues, we enable practitioners to train MoE models with RL more reliably, preserving all training data while eliminating the primary source of training-inference mismatch.
Pull Requests
- [BugFix] Capture logical routed experts reliably for replay: vllm-project/vllm#33013
- [megatron, training_utils] fix: router replay R3 align router replay data with global layer indices: volcengine/verl#5037
- [megatron, training_utils] fix: Patch MoEAlltoAllTokenDispatcher.preprocess for router replay: volcengine/verl#4986
- [doc, trainer] fix: shouldn't use rollout routing replay data for R2: volcengine/verl#4973
References
[1] Stabilizing Reinforcement Learning with LLMs: Formulation and Practices (Zheng et al, 2025)
[2] Let Speed Be With Stability: All-In-One Solution to Training-Inference Mismatch with Miles (Zhao et al, 2025)
[3] No More Train-Inference Mismatch: Bitwise Consistent On-Policy Reinforcement Learning with vLLM and TorchTitan (Wester et al, 2025)
[4] Defeating Nondeterminism in LLM Inference (He et al, 2025)
[5] Your Efficient RL Framework Secretly Brings You Off-Policy RL Training (Yao et al, 2025)
[6] When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch (Liu et al, 2025)
[7] Group Sequence Policy Optimization (Zheng et al, 2025)
[8] Clip Your Sequences Fairly: Enforcing Length Fairness for Sequence-Level RL (Ma et al, 2025)
[9] Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers (Ma et al, 2025)
[10] DeepSeek-V3 Technical Report (DeepSeek-AI et al, 2024)
[11] Qwen3 Technical Report (Yang et al, 2025)
[12] Defeating the Training-Inference Mismatch via FP16 (Qi et al, 2025)
Author
Mind Lab
Core Contributors
Steven Chiang, Irvine Lu, Kieran Liu, Andrew Chen, Pony Ma
Team
Andrew Chen, Kaijie Chen, Steven Chiang, Yuhua Jiang, Andrew Lei, Guanming Liu, Kieran Liu, Theo Li, Irvine Lu, Pony Ma, Warrior Xu, Alex Yin, Rio Yang and Mindverse Team
Names are listed alphabetically within team.
Citation
Please cite this work using the BibTeX citation:
@misc{chiang2026routerreplay, author = {Chiang, Steven and Irvine Lu and Kieran Liu and Chen, Andrew and Ma, Pony and {Mind Lab}}, title = {Router Replay R3: Why It Failed and How We Fixed It}, year = {2026}, howpublished = {Mind Lab: A Lab for Experiential Intelligence}, note = {https://macaron.im/mindlab/research/router-replay-r3-why-it-failed-and-how-we-fixed-it} }