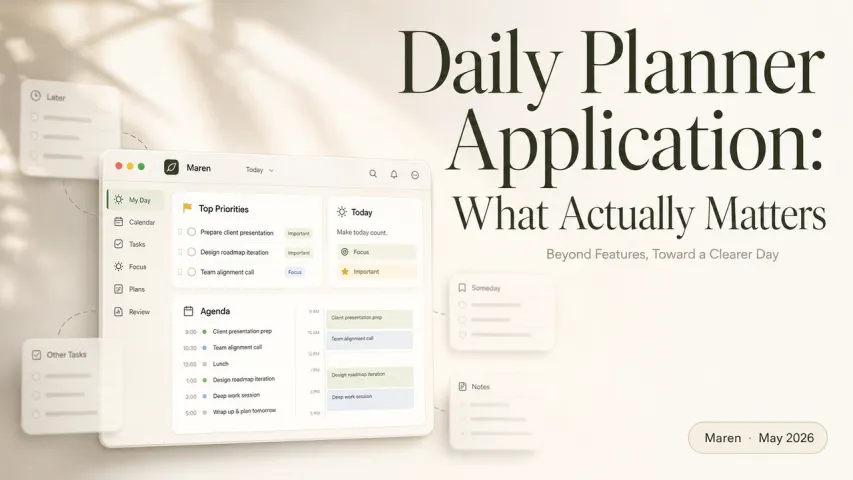
ပထမဆုံး qwen3 vl embedding ကို အပြင်မှာ အသုံးပြုတဲ့အခါမှာတော့ "အရမ်းကြည့်ကောင်းပေမယ့် အသုံးမဝင်တဲ့ နမူနာ" လို့ ထင်ထားတာပါ။
ဒါနဲ့ မထင်မှတ်ပဲ မေးလိုက်တော့ အရမ်းထူးဆန်းတဲ့မေးခွန်းတစ်ခုပါ။ "Notion နဲ့ Obsidian ကို ရှုထောင့်အသီးသီးကနေ လေဖြတ်ကုန်ကျစရိတ်ကို မူပေါ်တဲ့ ပန်းချီဗျူဟာနဲ့ ဖတ်စမ်း"ဆိုတဲ့စာရွက်ကို ရှာပါ။" အချိန်မီထဲမှာပဲ ပုံစံမမှန်တဲ့ screenshot, PDF, နှင့် မှတ်စုများကိုတွေ့ပါသည်။
ဒါတွင် အဓိကကျတဲ့ အချက်ကတော့ - ဒီဟာက သာမန် ဗက်တာရှာဖွေရန်သာမကဘဲ - Google Photos ရဲ့ "snow ထဲက ခွေး" မျိုးအဖြစ်ဖြစ်လာတဲ့ နည်းပညာကို ကိုယ်ပိုင် အသုံးချနိုင်အောင် ဖန်တီးပေးတဲ့ တည်ဆောက်ကိရိယာတစ်ခုဖြစ်ပါတယ်။ မော်ဒယ်တွေက qwen3 vl embedding လိုမျိုး အသုံးချနိုင်တဲ့ ရှာဖွေရန် လုပ်ငန်းစဉ်တွေကို ML နဲ့ PhD မလိုဘဲ သင့်ရဲ့ မှတ်စု app, အကြောင်းအရာစနစ်, သို့မဟုတ် indie SaaS ကိုလည်း အသုံးချနိုင်အောင် ဖန်တီးပေးပါတယ်။
"multimodal embedding" ဆိုတာ ဘာကိုဆိုလိုတာလဲ?
နည်းပညာစကားလုံးတွေကို ဖျက်လိုက်ကြစို့။
qwen3 vl embedding သို့မဟုတ် "multimodal embedding" လို့ ကြားရတဲ့အခါ -
"စာသားနဲ့ ပုံတွေကို နံပါတ်တွေ အဖြစ် ပြောင်းပြီး အဓိပ္ပာယ်တူ နေရာထဲမှာ တည်ရှိနိုင်အောင်လုပ်ရင်၊ အပြန်အလှန် ရှာတွေ့နိုင်ပါတယ်။"

အတိုချုပ်
ပုံမှန် စာသား embedding မော်ဒယ်ကတော့ အောက်ပါ စာကြောင်းကို ခံစားရပါတယ် -
"A cat sleeping on a laptop."
...နဲ့တူတဲ့နံပါတ်တွေရဲ့ရှည်လျားတဲ့စာရင်းကိုဖန်တီးပြီး၊ [0.12, -0.88, 0.03, ...] တို့လိုမျိုးဖြစ်ပါတယ်။ အဲ့ဒီစာရင်းကိုဗက်တာလို့ခေါ်ပါတယ်။ အဓိပ္ပါယ်တူသောဝါကျများသည်နီးကပ်သောဗက်တာများကိုရရှိသည်။
qwen3 VL ကဲ့သို့သော မျိုးစုံပုံစံထည့်သွင်းမှုမော်ဒယ် သည်အတူတူသောအရာကိုလုပ်သည်၊ သို့သော်:
- စာသားများ (မေးခွန်းများ၊ အကြောင်းအရာများ၊ မှတ်ချက်များ)
- ပုံများ (စခရင်ရှော့များ၊ အသေးစိတ်ပုံများ၊ UI အကြမ်းဖျဉ်းများ)
- တခါတရံ PDF များ၊ ကွက်တံများနှင့် အခြား "မြင်ရသော" အရာများ
လှည့်ကွက်က: မော်ဒယ်သည် အကုန်လုံးကို တူညီသောထည့်သွင်းမှုအာကာသသို့ မြေပုံဆွဲသည်။ အဲဒါကဆိုရင်:
- MacBook မှာကြောင်ရဲ့ပုံတစ်ပုံ
- "ကြောင်ကွန်ပျူတာပေါ်မှာအိပ်နေတယ်" စာသား
- "ကွန်ပျူတာကီးဘုတ်ပေါ်မှာအိမ်မွေးတိရစ္ဆာန်" ဆိုတဲ့စကားလုံး
...ဒီအရာအားလုံးသည် ဗက်တာအာကာသတစ်ခုတွင်နီးကပ်စွာတည်ရှိသည်။ အဲဒါဆိုရင် စာသားနဲ့ရှာဖွေရင် ပုံတွေကိုပြန်ခေါ်နိုင်တယ်။ အကြောင်းအရာအရ ပုံတွေကို ထည့်သွင်းပြီး အဓိပ္ပါယ်အရ စုစည်းနှင့် စီစဉ်နိုင်တယ်၊ ဖိုင်နာမည် သို့မဟုတ် ဖိုလ်ဒါအရမဟုတ်ပါ။
qwen3 VL ထည့်သွင်းမှုက အမှန်တကယ်ဘယ်လိုအလုပ်လုပ်သလဲ (သဘောတရားအရ)

အပြည့်အစုံသင်္ချာလိုအပ်ခြင်းမရှိပါ၊ ဒါပေမယ့် ငါသုံးတဲ့စိတ်ဓာတ်ပုံစံကတော့:
- ရုပ်ပုံ Encoder: ရုပ်ပုံကိုယူ → အပိုင်းအသီးသီးတွေအဖြစ်ခွဲခြား → ဗီရှင်အပြောင်းအလဲမှတဆင့်ပြေးသွား → ဗက်တာထုတ်ပေးသည်။
- စာသား Encoder: စာသားကိုယူ → အပိုင်းအစများအဖြစ်ခွဲခြား → ဘာသာစကားအပြောင်းအလဲမှတဆင့်ပြေးသွား → ဗက်တာထုတ်ပေးသည်။
- မျှဝေနေရာ: လေ့ကျင့်စဉ်အတွင်း၊ မော်ဒယ်ကို လိုက်ဖက်သည့် ရုပ်ပုံနှင့် စာသားများကို နီးစပ်သောနေရာတွင်ထားရန်နှင့် မလိုက်ဖက်သောအတွဲများကို ဝေးဝေးထားရန် ချိန်ညှိသည်။
ဒါကြောင့် သင် qwen3 vl embedding အလုပ်ဖြစ်စဉ်ကို အသုံးပြုသောအခါ:
- 10,000 screenshots ကို တစ်ကြိမ် embed လုပ်ပါ
- အဲဒီဗက်တာများကို ဒေတာဘေ့စ်ထဲသိမ်းပါ
- ရှာဖွေရန်အချိန်တွင် သင့်စာသားမေးခွန်းကို embed လုပ်ပါ
- "ဤစာသားဗက်တာနှင့် နီးစပ်သော ရုပ်ပုံဗက်တာများက ဘယ်လိုလဲ?" ဟု မေးပါ
…သင်သည် အဓိပ္ပာယ်ဖွင့်ဆိုချက်များရှိသော မူလဒေသများကို ရှာဖွေရန်ရသည်။ သင်၏ကိုယ်ပိုင်စိမ်းလန်းသောဖိုင်များပေါ်တွင် အလုပ်လုပ်နေသည်ကို ပထမဆုံးမြင်သောအခါ မှော်နှင့်တူသည်။
ငါ့စမ်းသပ်မှုများတွင် အသေးစားဒေတာအစု (screenshots 1,200 လောက် + PDF 300) အပေါ်တွင်၊ အခြေခံ qwen-style မူလဒေသ embedding အပြုပြင်မှုသည် စာသား → ရုပ်ပုံမေးခွန်းများကို "အမြင်ထင်မှတ်စရာကောင်းသော ထိပ်ဆုံး-၃ ရလဒ်" ဟု ငါခေါ်သောအရာကို 87–92% လောက်ဖြေဆိုခဲ့သည်။ "ရိုးရှင်းသော" အယူအဆများဖြစ်သည့် လိုဂိုများ၊ ဒက်ရှ်ဘုတ်များနှင့် စာရွက်များအတွက်၊ 95% နီးပါးနီးပါးဖြစ်သည်။
ယင်းသည် ပုံမှန် AI ရှာဖွေရန် နှင့် မတူဘဲ ခြားနားသည့် အရာများ
လူများသည် ယခင်က ကြိုးစားခဲ့သော "AI ရှာဖွေရန်" အများစုသည် သုံးခုတွင် တစ်ခုဖြစ်သည်။
- Keyword search (ရိုးရာ):
- စာလုံးတွေကို အစစ်အမှန်ကြည့်ပါတယ်။
- 「ငွေစာရင်း」 ≠ 「ကြွေးစာရင်း」 တို့ကို စိတ်ကြိုက်ပြုပြင်ခြင်းမရှိလျှင် မတူပါ။
- ရုပ်ပုံများသည် အခြားရေးသားချက်များ သို့မဟုတ် ဖိုင်အမည်များမရှိပါက မမြင်နိုင်ပါ။
- စာသားသာသာ အဓိပ္ပာယ်ရှာဖွေရေး (ပုံမှန် embeddings):
- သင်သည် စာသားကိုသာ embed လုပ်ပါ။
- စာရွက်စာတမ်းများ၊ စကားဝိုင်းမှတ်တမ်းများ၊ အချက်အလက်မြှင့်တင်ရေးများအတွက် အထူးသင့်လျော်သည်။
- ရုပ်ပုံများကို OCR မလုပ်ပါက မမြင်နိုင်ပါ။
- သင့်ဖိုင်များနှင့် စကားပြောကိရိယာများ:
- ပုံမှန်အားဖြင့် (2) အထက်တွင် အထုပ်များဖြင့် အပြုံးများဖြစ်သည်။
qwen3 vl embedding စတိုင် ဆက်တင်သည် သုံးခုအထူးတလည်ဖြင့် ကွာခြားသည်။
1. ရုပ်ပုံများသည် ရှာဖွေရေးတွင် ပထမတန်းသား ဖြစ်လာသည်
multimodal embeddings ဖြင့်:
- ရုပ်ပုံများနှင့် စာသားများသည် တူညီသော ရှာဖွေရေးအရာတွင် တည်ရှိသည်။
- တင်ပြချက်မလိုဘဲ ရုပ်ပုံများကို စာသားဖြင့် ရှာဖွေနိုင်သည်။
- သင်သည် နောက်ပြန်လည်လုပ်နိုင်သည်: ရှာဖွေရေးအဖြစ် ရုပ်ပုံကို အသုံးပြု၍ စာသားပါဝင်မှုကို ရှာဖွေနိုင်သည်။
ကျွန်ုပ်စမ်းသပ်ခဲ့သော ရှာဖွေရေး ဥပမာ:
「ကျွန်ုပ်သည် 60% မှာ အနီရောင်မြှောက်လုံးဖြင့် funnel drop-off ကို ပြသခဲ့သော slide။」
ရိုးရာရှာဖွေရေး: 0 အညီအမဲ့ (အကြောင်းမှာ "funnel" စကားလုံးသည် ဖိုင်အမည် သို့မဟုတ် စာသားတွင် မပါရှိသောကြောင့်)။
Multimodal embedding ရှာဖွေရေး: ~0.3 စက္ကန့်အတွင်း မှန်ကန်သော deck ကို ရှာဖွေတွေ့ရှိခဲ့ပြီး၊ အထိထိရောက်ရောက်သော slide ကို ထိပ်ဆုံး 2 ရလဒ်တွင် ရှာဖွေတွေ့ရှိခဲ့သည်။
2. မတည်ငြိမ်သော OCR မှီခိုမှုမရှိတော့ပါ
ပုံမှန် AI ရှာဖွေရေးဖြင့်၊ ရုပ်ပုံများအတွက် ပုံမှန် "ဖြေရှင်းချက်" သည်:
- OCR ကို ပြုလုပ်ပါ။
- ထုတ်ယူထားသော စာသားကို အခြားစာသားများကဲ့သို့ ဆက်ဆံပါ။
ပြဿနာများ:
- အဆိုးဆုံး screenshots? OCR မအောင်မြင်ပါ။
- ခေါင်းစဉ်ပါသောဇယားများ? OCR သည် အပိုင်းအစများကို ပေးသည်။
- UI mockups? သင်သည် အပိုင်းအစ ID များနှင့် အဓိပ္ပါယ်လွဲမှားမိသည်။
qwen3-စတိုင် VL embeddings ဖြင့်၊ ရှုထောင့်ဖွဲ့စည်းမှု (အပြင်အဆင်၊ ဇယားပုံစံများ၊ အရောင်ပုံစံများ) ကို ရှာဖွေနိုင်သည်။
- "Dark theme dashboard with a line chart and purple accent"
- "Pricing page with three columns and the middle one highlighted"
ဤမေးခွန်းများသည် အမှန်တကယ်အမှန်ဖြစ်သောအရာကို ပိုမိုရရှိသည်။ ကျွန်ုပ်၏ စမ်းသပ်မှုများတွင်၊ OCR သာမန်ရှာဖွေမှုသည် UI mockups တွင် 55–60% ကောင်းသောကိုက်ညီမှုရရှိခဲ့သည်။ multimodal embeddings က 85%+ အထိ တိုးတက်လာခဲ့သည်။
3. ပိုမိုကောင်းမွန်သော ရှာဖွေမှု → ပိုမိုကောင်းမွန်သော ဖန်တီးမှုအဖြေများ
RAG (retrieval augmented generation) ကို သင်လုပ်နေပါက၊ သင့် LLM အဖြေများသည် ထူးချွန်စွာဖြစ်မလား၊ အဓိပ္ပါယ်ကင်းမဲ့ဖြစ်မလားကို သင့် ရှာဖွေမှုအရည်အသွေးက ဆုံးဖြတ်သည်။
စာသားသာဖြင့် RAG:
- အရွယ်ကြီးသောစာရွက်စာတမ်းများနှင့် မကြာခဏမေးလေ့ရှိသောမေးခွန်းများအတွက် အထူးသင့်လျော်သည်။
- သင့် dashboard များ၊ Miro board များ၊ Figma အပြင်အဆင်များ၊ whiteboard ဓာတ်ပုံများကို မြင်နိုင်ခြင်းမရှိပါ။
RAG အတွက် qwen3 vl embedding workflow:
- သင့်လျော်သော ပုံတစ်ပုံနှင့် အနီးဆုံးစာသားအနီးကပ်များကို ရယူပါ။
- နှစ်မျိုးပေါင်းစပ်ထားသော LLM သို့ နှစ်ခုလုံးကို ထည့်ပါ။
- ဇယားကို မှတ်သားသော အဖြေများကို ရယူပါ၊ ခန့်မှန်းခြင်းမဟုတ်ပါ။
Multimodal retriever ကို ရိုးရှင်းသော အာနလိစ်တစ်ခု၏ Q&A bot ထဲသို့ ထည့်သောအခါ၊ "တကယ်မှန်ကန်သောဇယားထဲတွင် အခြေခံထားခြင်း" အချိုးမှာ 50 စမ်းသပ်မေးခွန်းများအတွက် 70% လောက်မှ 93% အထိ မြင့်တက်ခဲ့သည်။ LLM တူညီပေမယ့် ရှာဖွေမှုက ပိုမိုကောင်းမွန်သည်။
သင့်အတွက်အသုံးပြုပြီးသား တကယ့်နမူနာများ (Google Photos, Pinterest)

မင်းက multimodal embedding ဆိုတဲ့စကားလုံးကို မကြားဖူးပေမယ့် သုံးဖူးတာတော့ သေချာပါတယ်။
Google Photos: မိတ်ဆွေလိုမျိုးသော multimodal lab
အောက်ပါအတိုင်း Google Photos မှာ ရိုက်ထည့်ပါ:
- "ဆီးနင်းထဲမှာ ခွေး"
- "2019 မွေးနေ့ ကိတ်မုန့်"
- "လမ်းကြောင်းပြ မြေပြင်"
တကယ့်ကိုမှန်ကန်တဲ့ ဓာတ်ပုံတွေကို တွေ့ရပါမယ်၊ သို့သော်:
- ဖိုင်နာမည်တွေက IMG_9843.JPG ဖြစ်ပါတယ်။
- မည်သူမှ "လမ်းကြောင်းပြ" ဆိုတာ ဖတ်မထားပါ။
အောက်မှာဖြစ်စဉ်ကို qwen3 vl embedding စနစ်နဲ့ ဆင်တူပါတယ်:
- ပုံတွေကို ဗက်တာတွေထဲမှာ encode လုပ်ပါတယ်။
- မင်းရဲ့ စာသားမေးခွန်းကို ဗက်တာထဲမှာ encode လုပ်ပါတယ်။
- စနစ်က နီးကပ်တဲ့ ဗက်တာတွေနဲ့ ပုံတွေကို ရှာဖွေပါတယ်။
ဦးနှောက်ဖတ်တာမဟုတ်ပါဘူး။ ကျွန်ုပ်တို့ရဲ့ သိပ္ပံနည်းကျမျှတသော စွမ်းဆောင်ရည်ကြီးတဲ့ မက်စ်ကို သုံးပါတယ်။
Pinterest ဓာတ်ပုံ ရှာဖွေရန်: Vibe နဲ့ ရှာပါ
Pinterest ရဲ့ visual search ("အလားတူ pins တွေရှာပါ") က multimodal embedding ရှာဖွေရေးရဲ့ ထူးချွန်တဲ့ ဥပမာတစ်ခုပါ။
ဓာတ်ပုံထဲက မီးခွက်ကို ကလစ်နှိပ်လိုက်တယ်ဆိုပါစို့ → ချက်ချင်း အခန်းတွေ၊ အရောင်တွေ၊ ပုံစံတွေကွဲပြားတဲ့ မီးခွက် 40 ခုကို တွေ့ရပါတယ်။ အသေးစိတ် လုပ်ငန်းစဉ်က qwen3 VL မှာ ကွဲပြားပေမယ့် အဓိကစိတ်ကူးကတူပါတယ်: ဗက်တာထဲမှာ အကြောင်းအရာတွေကို embed လုပ်ပြီး နှိုင်းယှဉ်ပါ။
ဒါက အခြေအနေတွေကို ပြသနိုင်တဲ့ အကြောင်းပါ:
- အလားတူ အရုပ်ပြမှုတွေ
- အလားတူ အရောင်တွေ
- အတိအကျ တွေ့မှုမဟုတ်ဘဲ၊ အလားတူခံစားချက်တွေ
အခုကွာခြားချက်: မင်းကိုယ်တိုင် အခုလုပ်နိုင်ပြီ
ကဲ့သို့သော မော်ဒယ်များ qwen3 VL နှင့် ၎င်း၏ တူညီသူများသည် ယခင်တွင် သက်ဆိုင်ရာ အခြေခံအဆောက်အအုံများကို စွမ်းအားအရှိဆုံး အရာတစ်ခုအဖြစ် ပြောင်းလဲရန် သင့်ရဲ့ ကျွမ်းကျင်မှုကို သင့်တစ်ကိုယ်ပိုင် လုပ်ငန်းများတွင် ထည့်သွင်းနိုင်သော အရာတစ်ခုအဖြစ် ပြောင်းလဲနေကြသည်။
တိကျစွာဆိုရသော် သင်၏ အပလီကေးရှင်းအတွက် အခြေခံ qwen3 vl embedding လုပ်ငန်းစဉ်မှာ အောက်ပါအတိုင်း ဖြစ်ပါသည် -
Ingestion:
- ပုံများ / PDF များ / စာမျက်နှာများကို ယူပါ။
- ၎င်းတို့ကို VL embedding မော်ဒယ်မှ တဆင့် လည်ပတ်ပါ။
- ဗက်တာဒေတာဘေ့စ် (ဥပမာ- Qdrant, Weaviate, Pinecone, pgvector) တွင် ဗက်တာများကို သိမ်းဆည်းပါ။
ရှာဖွေရန်:
- အသုံးပြုသူ၏ စာသားမေးခွန်းကို ယူပါ။
- အတူတူသော မော်ဒယ်ဖြင့် embed လုပ်ပါ။
- အနီးဆုံး အိမ်နီးချင်းရှာဖွေရန် လုပ်ဆောင်ပါ။
ပြသရန်:
- မူရင်းပုံ / စာမျက်နှာ + သက်ဆိုင်ရာ အချက်အလက်များကို ပြန်လည်ပေးပါ။
ဝယ်သူအတွက် ကျွန်ုပ် ပြုလုပ်ထားသော သေးငယ်သော စမ်းသပ်မှုတစ်ခုတွင် (အလားတူ 3,500 ဒီဇိုင်း အရင်းအမြစ်များနှင့် စကရင်ရှော့များ) ဂွမ်စတိုင် မော်ဒယ်များသုံးသော မော်ဒယ်များမှ filename/tag ရှာဖွေရန်မှ မော်တစ်ခုဖြင့် ရှာဖွေရန်သို့ ပြောင်းလဲခြင်းဖြင့် -
- "မှန်ကန်သော အရင်းအမြစ်ကို ရှာဖွေရန် အချိန်" ကို အသုံးပြုသူ စမ်းသပ်မှုများတွင် ~40–60% ဖြတ်တောက်ခဲ့သည်။
- "အရင်းအမြစ်ကို ထပ်မံဖန်တီးခဲ့ရသည်" အချိန်ကို အပတ်စဉ်မှ မျှော်မှန်းထားသောအခါ အလားတူသို့ ကျဆင်းခဲ့သည်။
ကိုယ်ပိုင် AI ကိရိယာများအတွက် ဒီအရာက အမြတ်တစ်ခု ဖြစ်တဲ့ အကြောင်း
ဒီမှာ indie ဖန်တီးသူများ၊ စာရေးဆရာများ၊ နည်းပညာစွမ်းပကားများအတွက် စိတ်ဝင်စားဖွယ် ဖြစ်နေပါပြီ - သင်သည် တော်တော်များများသော မော်ဒယ်များကို စီမံထားပြီးဖြစ်သည်။ သင်သည် ၎င်းတို့ကို တိကျစွာ ရှာဖွေရန် မရနိုင်ခဲ့ပါ။
သင့်ရဲ့ ကိုယ်ပိုင် အမှန်တရားသည် မော်ဒယ်များစွာဖြင့်ဖြစ်သည်
သင့်ရဲ့ အလုပ်ခန်းကို စဉ်းစားကြည့်ပါ:
- စကရင်ရှော့ဖိုလ်ဒါ (UI အကြံဉာဏ်များ၊ ယှဉ်ပြိုင်သူများ၊ အစီရင်ခံစာများ)
- စာမျက်နှာများ (ဝယ်သူတင်သွင်းမှုများ၊ သင်တန်းပေးမှု အကြောင်းအရာများ)
- အဖြစ်မှန်ပုံရိပ်များ (ထူးခြားသော အမြင်များ၊ အလင်းအိမ်ကောင်းစွာ မရရှိနိုင်သော)
- PDF များ (အစီရင်ခံစာများ၊ eBooks များ၊ ငွေပေးချေမှုများ)
ရိုးရာ "AI မှတ်စု" ကိရိယာတစ်ခုသည် စာသားပိုင်းကို ပျော်ရွှင်စွာ ရှာဖွေပါလိမ့်မည်။ အတိအကျပြောရရင် အခြားအရာအားလုံးသည် အမှောင်ထုပင် ဖြစ်သည်။ qwen3 vl embedding စနစ်တစ်ခုကို တပ်ဆင်ပြီးပါက မင်းရဲ့ AI အကူအညီပေးသူက ရုတ်တရက်:
- မင်းရဲ့ အမှတ်မှားနေတဲ့ slide ကို ရှာဖွေနိုင်သည်
- သူငယ်ချင်းအကျဉ်းချုပ်ထဲမှာ မှန်ကန်တဲ့ဇယားကို ထည့်နိုင်သည်
- မမှန်မကန်စာသားဖေါ်ပြချက်အပေါ် အခြေခံပြီး UI အကြံဉာဏ်ကို ရှာဖွေနိုင်သည်
ကျွန်တော့်ရဲ့ ကိုယ်ပိုင် setup မှာတော့ FastAPI ဝန်ဆောင်မှုသေးသေးလေး + ဗက်တာ DB + qwen-like VL embedding မော်ဒယ်ကို ချိတ်ဆက်ထားပါတယ်။ အခုတော့:
- ရိုက်ပါ: "Q2 မှာ churn နဲ့ activation ကို အနီရောင်ဘားနဲ့ နှိုင်းယှဉ်ထားတဲ့ slide။"
- ရယူပါ: မှန်ကန်သော slide + အခြားအမျိုးမျိုးသော decks မှ နီးပါးသော ဗားရှင်းနှစ်ခု။
ဒီအရာတစ်ခုကိုပင် တစ်နေ့ကို ၁၀–၁၅ မိနစ်ခန့် "အဲ့ဒီအရာဘယ်မှာလဲ" ရှာဖွေရေးတွေကို ကယ်တင်ပေးနိုင်ခဲ့ပါတယ်။
ပိုမိုကောင်းမွန်သော ကိုယ်ပိုင် RAG စနစ်များ
RAG နဲ့ "ဒုတိယဉာဏ်" တည်ဆောက်ဖို့ ကြိုးစားနေသူများအများစုသည် အတူတူသော နံရံကို ရင်ဆိုင်ကြသည်:
ကျွန်ုပ်၏မှတ်စုများသည် ရှာဖွေနိုင်သော်လည်း စိတ်ဝင်စားဖွယ်ရာအရာများသည် screenshots နှင့် slides အတွင်းတွင် နေထိုင်ကြသည်။
ကိုယ်ပိုင်အသိပညာအတွက် qwen3 vl embedding အလုပ်流程သည်:
အရာအားလုံးကို အညွှန်းပြုပါ:
- စာသားဖိုင်များ → စာသား embedding များ။
- ပုံများ/slide များ/PDF များ → VL embedding များ။
Modalities များကို ချိတ်ဆက်ပါ:
- အညွှန်းများကို သိမ်းဆည်းပါ၊ ထို့ကြောင့် မည်သည့်ပုံမျှမရှိသောအခါ၊ သက်ဆိုင်ရာစာသားပိုင်းများ (caption, အစည်းအဝေးမှတ်စုများ, စာရွက်အကျဉ်းချုပ်များ) ကို ရည်ညွှန်းပါ။
မေးခွန်းအချိန်တွင်:
- မေးခွန်းကို စာသားနှင့် VL မော်ဒယ်များနှင့် တွဲဖက်၍ embed လုပ်ပါ (သို့မဟုတ် shared ဖြစ်လျှင် VL သာလျှင် embed လုပ်ပါ။)
- သက်ဆိုင်ရာ စာသားနှင့် ပုံများကို ရှာဖွေပါ။
- အားလုံးကို LLM (မီဒီယာမျိုးစုံဖြစ်ရမည်) သို့ ပေးပို့၍ ဖြေဆိုပါ။
မင်းရဲ့အဖြေများသည်:
"Here's your Q2 churn vs activation slide, and based on the chart your activation rate improved from ~26% to ~34% between April and June. The note you wrote alongside it says the change was due to the new onboarding experiments."
Instead of:
"I couldn't find anything relevant."
More honest trade-offs
It's not all magic. Some real limitations I hit testing qwen-style VL embeddings:
- Small text in images can still be rough. Tiny axis labels or dense tables don't always land well.
- Highly abstract queries like "slide where I felt stuck" obviously won't work.
- Domain-specific diagrams (e.g., niche engineering notations) may need fine-tuning or hybrid methods.
But even with these caveats, the jump from "only text is searchable" to "text + visuals share one meaning space" is big enough that I'm now reluctant to use any personal AI tool that doesn't offer some kind of multimodal embedding search.
What's next for this technology

If we zoom out, qwen3 vl embedding is part of a bigger trend: models are getting better at understanding the world (across text, images, maybe audio/video) in a single, coherent space.
Here's where I see this going in the next 12–24 months, based on how things are already shifting.
1. Multimodal embeddings baked into more tools by default
ယခုအခါမှာ မင်းအနေနဲ့ အရာတွေကို ကိုယ်တိုင်ပဲ ပေါင်းစည်းရပါတယ်:
- VL မော်ဒယ်ကို ရွေးပါ
- ဗက်တာ DB ကို ရွေးပါ
- ငှက်သောက်ပိုက်လိုင်းကို ရေးပါ
တစ်ချိန်မှာတော့ ပရိုဂရမ်တွေဟာ တစ်ခုထဲမှာ စွယ်စုံစွယ်စုံတာများ၊ ပုံရိပ်များကို ရှာဖွေရန် အင်္ဂျင်တွေနဲ့ ဖွင့်လှစ်ပါလိမ့်မယ်:
- မင်းရဲ့ စကရင်ရှော့တွေကို အလိုအလျောက် အညွှန်းတပ်ပေးတဲ့ မှတ်စုအက်ပ်များ
- အစည်းအဝေးဓာတ်ပုံတွေကို အဖြူဘုတ်အကြောင်းအရာအဖြစ် ရှာနိုင်တဲ့ ပရိုဂရမ်များ
- အပြင်အဆင်၊ အရောင်၊ UI ဖွဲ့စည်းပုံကို "နားလည်တဲ့" Asset မန်နေဂျာများ
ဒါဖြစ်လာရင် လူတွေက "ဗက်တာ DB" နဲ့ "VL မော်ဒယ်" ဆိုတာတွေ ပြောပြောနေရတာ မရပ်တော့ဘူး၊ "ဟုတ်ကဲ့၊ အခုဆိုရင် ငါ့ပစ္စည်းတွေကို ပုံဖော်ရေးနဲ့ ရှာနိုင်ပြီ။"
2. ရှာဖွေမှုနဲ့ ဖန်တီးမှုအကြား ပိုမိုကြည့်ရှုနိုင်တဲ့ အချိန်ကာလများ
ယခုအချိန်မှာတော့ RAG သတ်မှတ်ချက်တွေဟာ အများစုက:
- အတွင်း
- ရှာဖွေမှု
- LLM ထဲကို ပစ်လိုက်ပါ
မော်ဒယ်ဟာ:
- ဘာအကြောင်းအရာလိုအပ်သလဲဆိုတာ စီစဉ်ဖို့ မူလပုံရိပ်များကို သုံးပါ
- ပထမဆုံးအကြိမ်မှာ အားနည်းရင် ပုံရိပ်များ သို့မဟုတ် စာသားများ ပိုမိုမေးပါ
- သီးခြားဆက်စပ်မှုမော်ဒယ်ကို အသုံးပြု၍ ရလဒ်များကို ပြန်စီစဉ်ပါ
ကျွန်တော့်ကိုယ်ပိုင် အတွေ့အကြုံများအရ မူလပုံရိပ်များကို ရှာဖွေမှုအပေါ်မှာ မှန်ကန်မှုကို တိုးတက်စေဖို့ ရှင်းလင်းရေးကို ထည့်သွင်းတာက ~78% မှ 90% အထိ တိုးတက်စေပါတယ် မိမိ၏ စာတမ်း + စကရင်ရှော့ဒေတာစနစ်အတွက်။
3. ဖန်တီးသူများအတွက် ကိုယ်ပိုင် "မြင်ရည်မှတ်ဉာဏ်"
အထူးသဖြင့် တစ်ကိုယ်တော်ဖန်တီးသူများနှင့် စျေးကွက်ရှာဖွေရေးများအတွက် အရေးပါတဲ့ တစ်ခုက မြင်ရည်မှတ်ဉာဏ်အလွှာဖြစ်ပါတယ်:
- မင်းစမ်းသပ်ခဲ့တဲ့သေးငယ်တဲ့ပုံတိုင်း
- မင်းရိုက်ခဲ့တဲ့ကြော်ငြာဖန်တီးမှုတိုင်း
- မင်းတင်ပြခဲ့တဲ့ဆလိုက်ဒ်တိုင်း
- မင်းရောက်ရှိခဲ့တဲ့လန်းဒင်းစာမျက်နှာကွဲပြားမှုတိုင်း
qwen3 vl embedding workflow တစ်ခုမှတစ်ကြိမ် embed လုပ်ပြီးတဲ့အခါ မင်းမေးနိုင်တာက:
- ">5% CTR ရခဲ့တဲ့ကြော်ငြာဖန်တီးမှုနဲ့ဆင်တူတဲ့အရာတွေပြပါ။"
- "အနက်ရောင်နောက်ခံနဲ့လိမ္မော်ရောင်စာသားကိုသုံးခဲ့တဲ့အရင်ကသေးငယ်တဲ့ပုံတွေရှာပါ။"
- ">8% ပြောင်းလဲမှုရခဲ့တဲ့လန်းဒင်းစာမျက်နှာတွေမှာမင်းဘာပုံစံတွေသုံးခဲ့သလဲ?"
ဒါကိုသုံးသပ်ချက်တွေနဲ့ချိတ်ဆက်ပြီးတော့ မင်းရှာဖွေရုံမျှမကောင်းဘူး၊ ဖျော်ဖြေရေးအထိရောက်မှုရှိတဲ့အရာတွေကိုရှာဖွေနိုင်ပါတယ်။
4. အန္တရာယ်များနှင့်စောင့်ရှောက်ရန်အရာများ
ဒီကိုအခြေခံထားဖို့အတွက်၊ မင်းစမ်းသပ်ပြီးမူကွဲဖန်တီးမှုစနစ်များကိုအကြံပြုတဲ့အခါ သတိထားရမယ့်အရာအချို့:
- ကိုယ်ရေးအချက်အလက်: Screenshots နဲ့ slides တွေကို အခြားသူ API ကိုပေးပို့တာက client အလုပ်အတွက်တစ်ခါတစ်ရံမဖြစ်နိုင်ပါဘူး။ Self-hostable VL မော်ဒယ်တွေ (qwen-style အပါအဝင်) ကဒီမှာအရေးကြီးလာပါမယ်။
- အကျိုးသက်ရောက်မှု: ရုပ်ပုံထောင်ချီခြင်းကအခမဲ့မဟုတ်ပါဘူး။ တစ်ကြိမ်သာ index လုပ်ရင်အဆင်ပြေပါတယ်၊ ဒါပေမယ့် အသက်ရှင်တဲ့ဗီဒီယိုဖရိမ်တွေသို့မဟုတ်မကြာခဏနောက်ဆုံးထွက်လာတဲ့အရာတွေကိုထည့်ရင် tokens နဲ့ GPU စရိတ်တွေကိုသတိထားဖို့လိုပါတယ်။
- အကဲဖြတ်ခြင်း: ရှာဖွေရေးကကောင်းတယ်လို့ခံစားရတာလွယ်ပါတယ်။ အကောင်းဆုံးကတော့:
- လေးကွက်တစ်ခုအတိအကျမှုကိုပေးထားတဲ့မေးခွန်းအစုအပေါ်မှာ
- မင်းရဲ့နေ့စဉ်အလုပ်မှာ "Time to asset"
- မင်းဟာတစ်ခါတစ်ရံပြန်လည်ဖန်တီးဖို့လက်လျှော့ရတာဘယ်နှစ်ကြိမ်ဖြစ်သလဲ

မင်းစိတ်ဝင်စားရင်ကျွန်တော့်အကြံပြုချက်
အကယ်၍ သင်သည် AI ကိရိယာများကို ရှာဖွေရန် စတင်ပြီးသားဖြစ်ပါက၊ ကျွန်ုပ်၏ အမှန်တကယ် အကြံပြုချက်မှာ- မူလချုပ်ပုံစံများနှင့်အတူ သေးငယ်သော စမ်းသပ်မှုတစ်ခုကို လုပ်ဆောင်ပါ။
ရုပ်ပုံအလွှာများ — screenshots ဖိုလ်ဒါ၊ စာရွက်တင်ပို့မှုများ၊ Pinterest ဘုတ်အဖွဲ့ ထုတ်ယူမှုများ၊ အကြောင်းအရာမရွေး။ အလွယ်တကူ qwen3 vl embedding ရှာဖွေရန် ချိတ်ဆက်ပါ။ ဗက်တာ DB သို့မဟုတ် စမ်းသပ်မှုအတွက် disk အညွှန်းကို အသုံးပြုပါ။
လူတစ်ဦးကလို ရှာဖွေရန် တစ်ပတ်ကြာ စမ်းသပ်ပါ:
- "အဲဒီ စာရွက်တစ်ရွက်..."
- "ပြသခဲ့သော ဒက်ရှ်ဘုတ်..."
- "အပြုံးပုံနှင့် အပြာရောင် နောက်ခံရှိ ကြော်ငြာ..."
သင်၏ အတွေ့အကြုံသည် ကျွန်ုပ်၏ အတွေ့အကြုံနှင့် တူပါက၊ embedding များကို ရိုးရှင်းသော အင်ဖရာစကားလုံးအဖြစ် မထင်တော့ပဲ 'ကျွန်ုပ်၏ အရာဝတ္ထုများသည် အမိုက်ထဲ' နှင့် 'ကျွန်ုပ်၏ အရာဝတ္ထုများသည် ကျွန်ုပ်၏ မှတ်ဉာဏ်၏ အဖွဲ့ဝင်တစ်ခုဖြစ်သည်' အဖြစ် ထင်မြင်မည်ဖြစ်သည်။
အဲဒါဖြစ်ပြီးလျှင်၊ ပြန်သွားဖို့ ကြိုးစားရခက်ပါသည်။
မော်ဒယ်အကြောင်း: Qwen3-VL-Embedding ကို 2026 ခုနှစ် ဇန်နဝါရီလ 8 ရက်နေ့တွင် Alibaba ၏ Qwen အဖွဲ့မှ ဖြန့်ချိခဲ့ပါသည်။ 30 ကျော်သော ဘာသာစကားများကို ပံ့ပိုးပေးပြီး၊ MMEB-v2 (79.2 စုစုပေါင်းအမှတ်) နှင့် MMTEB (74.9 with reranker) ကဲ့သို့သော မူလချုပ်ခွဲခြားမှုများတွင် အထူးပြုခဲ့ပါသည်။ ဤမော်ဒယ်သည် အခမဲ့ဖြစ်ပြီး Hugging Face, GitHub, နှင့် ModelScope တွင် ရရှိနိုင်ပါသည်။