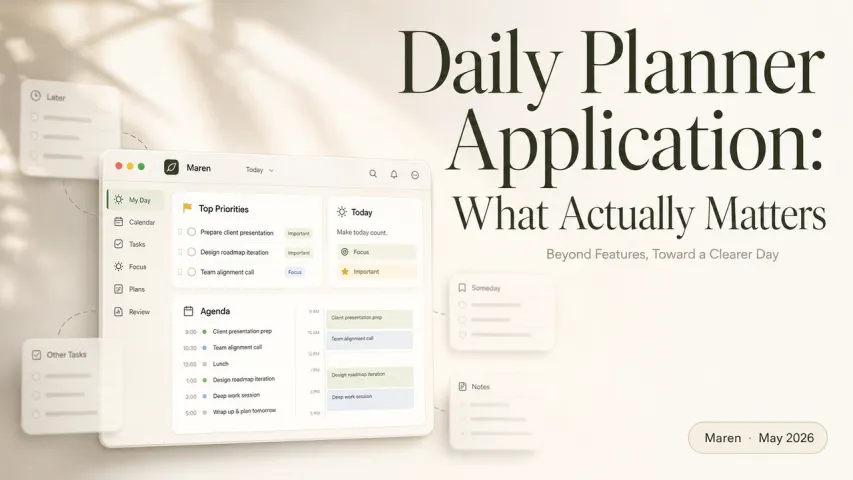
Noong una kong ginamit ang qwen3 vl embedding sa isang totoong workflow, inasahan kong isa na namang "cool demo, useless in practice" na sandali.
Sa halip, tinanong ko ito ng kakaibang tanong: "Hanapin ang slide kung saan ko ikinumpara ang Notion vs Obsidian gamit ang isang purple na graph at binanggit ang 'friction cost'." Nahanap nito ang eksaktong slide mula sa magulong folder ng mga screenshot, PDF, at tala sa ilalim ng isang segundo.
Doon ko napagtanto: hindi lang ito mas magandang vector search. Ito ay multimodal embedding sa ligaw – ang parehong ideya sa likod ng "dog in snow" magic ng Google Photos, na ngayon ay magagamit bilang building block para sa sarili nating mga tool. At ang mga model tulad ng qwen3 vl embedding ay ginagawa ang antas na ito ng paghahanap na maaari mong idagdag sa iyong notes app, content system, o indie SaaS nang hindi kailangan ng PhD sa ML.
Ano ang ibig sabihin ng "multimodal embedding"?
Tanggalin natin ang jargon.
Kapag narinig mo ang qwen3 vl embedding o "multimodal embedding," isipin:
"I-convert ang teksto at mga imahe sa mga numero na nabubuhay sa parehong meaning-space para mahanap nila ang isa't isa."

Ang maikling bersyon
Ang isang regular na text embedding model ay kumukuha ng isang pangungusap tulad ng:
"Isang pusa na natutulog sa laptop."
…at ginagawa itong isang mahabang listahan ng mga numero, parang ganito [0.12, -0.88, 0.03, ...]. Ang listahang iyon ay tinatawag na vector. Ang mga pangungusap na may katulad na kahulugan ay nagkakaroon ng mga vector na magkalapit.
Ang multimodal embedding model gaya ng qwen3 VL ay gumagawa ng parehong bagay, pero para sa:
- Teksto (mga query, caption, tala)
- Mga Larawan (screenshot, thumbnail, UI mockup)
- Minsan PDFs, diagram, at iba pang "visual-ish" na bagay
Ang sikreto: ang modelo ay nagmamapa sa lahat ng ito sa parehong embedding space. Ibig sabihin:
- Isang larawan ng pusa sa isang MacBook
- Ang teksto "pusang natutulog sa laptop"
- Ang pariralang "alagang hayop sa keyboard ng computer"
…lahat ay napupunta malapit sa isa't isa sa vector space na ito. Kaya kapag naghahanap ka gamit ang teksto, maaari kang makakuha ng mga larawan. Kapag ini-embed mo ang iyong mga larawan, maaari mo itong ayusin at i-cluster ayon sa kahulugan, hindi ayon sa filename o folder.
Ano talaga ang ginagawa ng qwen3 VL embedding sa ilalim (konseptwal)

Hindi mo kailangan ang buong matematika, pero narito ang mental model na ginagamit ko:
- Image encoder: Kinuha ang isang larawan → hinahati ito sa mga patch → dumadaan sa isang vision transformer → naglalabas ng vector.
- Text encoder: Kinuha ang teksto → ginagawang mga token → dumadaan sa isang language transformer → naglalabas ng vector.
- Shared space: Sa panahon ng pagsasanay, ang modelo ay pinipilit na gawing magkalapit ang magkatugmang mga larawan at teksto, at ang hindi magkatugmang mga pares ay ilagay na malayo.
Kaya kapag gumamit ka ng isang qwen3 vl embedding workflow tulad ng:
- I-embed ang 10,000 screenshot nang isang beses
- I-imbak ang mga vector na iyon sa isang database
- Sa oras ng paghahanap, i-embed ang iyong text query
- Magtanong "alin sa mga image vector ang pinakamalapit sa text vector na ito?"
…makakakuha ka ng semantic multimodal search. Parang mahika ito kapag una mong nakita itong gumana sa iyong sariling magulong mga file.
Sa aking mga pagsubok sa isang maliit na dataset (mga 1,200 screenshot + 300 PDF), isang basic na qwen-style multimodal embedding setup ay nakasagot sa text → image queries na may tinatawag kong "visually correct top-3 results" sa mga 87–92% ng oras. Para sa "simple" na mga konsepto tulad ng mga logo, dashboard, at slide, ito ay mas malapit sa 95%.
Paano ito naiiba sa regular na AI search
Karamihan sa "AI search" na sinubukan ng mga tao sa ngayon ay nahuhulog sa isa sa tatlong kategorya:
- Paghahanap gamit ang keyword (klasiko):
- Literal na tinitignan ang mga salita.
- "invoice" ≠ "resibo" maliban kung mano-manong aayusin.
- Ang mga imahe ay hindi nakikita maliban kung may alt text o pangalan ng file.
- Paghahanap gamit ang semantic na text lamang (regular embeddings):
- I-embed mo lang ang teksto.
- Magaling para sa mga dokumento, kasaysayan ng chat, base ng kaalaman.
- Ang mga imahe ay nanatiling hindi malinaw maliban kung sila ay na-OCR.
- Makipag-chat gamit ang mga tool sa iyong mga file:
- Karaniwang mga balot lang sa paligid ng (2) + ilang mga trick sa prompt.
Ang isang qwen3 vl embedding style setup ay naiiba sa tatlong pangunahing paraan.
1. Ang mga imahe ay nagiging pangunahing mamamayan
Sa pag-embed ng multimodal:
- Ang mga imahe at teksto ay nasa parehong search space.
- Maaari mong hanapin ang mga imahe gamit ang teksto nang walang mga caption.
- Maaari mo ring gawin ang kabaligtaran: hanapin ang nilalaman ng teksto gamit ang isang imahe bilang query.
Halimbawa ng query na sinubukan ko:
"Ang slide kung saan ipinakita ko ang funnel drop-off na may pulang arrow sa 60%."
Tradisyunal na paghahanap: 0 na tugma (dahil ang salitang "funnel" ay hindi lumabas sa pangalan ng file o teksto).
Paghahanap gamit ang multimodal embedding: natagpuan ang tamang deck sa ~0.3s, kasama ang tamang slide sa nangungunang 2 resulta.
2. Walang maselan na dependency sa OCR
Sa regular na AI search, ang default na "solusyon" para sa mga imahe ay:
- Patakbuhin ang OCR.
- Ituring ang nakuha na teksto tulad ng anumang ibang teksto.
Mga problema:
- Masasamang screenshot? Nabigo ang OCR.
- Mga tsart na may label? Nagbibigay sa iyo ang OCR ng mga pira-piraso.
- Mga mockup ng UI? Makakakuha ka ng mga bahagyang ID at walang katuturan.
Sa pamamagitan ng qwen3-style VL embeddings, nagiging searchable ang visual na istruktura (layout, hugis ng chart, pattern ng kulay):
- "Dark theme dashboard na may line chart at purple accent"
- "Pricing page na may tatlong column at naka-highlight ang gitna"
Madalas na tama ang mga query na ito. Sa aking mga pagsubok, nakakuha ang OCR-only search ng mga 55–60% na tamang tugma sa mga UI mockup: ang multimodal embeddings ay nagtulak dito sa 85%+.
3. Mas mahusay na retrieval → mas mahusay na generative na mga sagot
Kung ginagawa mo ang RAG (retrieval augmented generation), tahimik na tinutukoy ng kalidad ng iyong retrieval kung matalino o walang saysay ang mga sagot ng iyong LLM.
Text-only RAG:
- Magaling para sa mahahabang dokumento at mga FAQ.
- Bulag sa iyong mga dashboard, Miro board, Figma design, mga larawan sa whiteboard.
Isang qwen3 vl embedding workflow para sa RAG:
- Mag-retrieve ng kaugnay na imahe at ang pinakamalapit nitong mga text neighbor.
- I-feed ang pareho sa isang multimodal LLM.
- Makakuha ng mga sagot na aktwal na nagre-refer sa diagram, hindi lang hula.
Nang ikabit ko ang isang multimodal retriever sa isang simpleng analytics Q&A bot, ang "aktwal na nakabatay sa tamang chart" rate ay tumaas mula sa humigit-kumulang 70% hanggang 93% sa 50 test questions. Parehong LLM, mas mahusay lang na retrieval.
Mga tunay na halimbawa na nagamit mo na (Google Photos, Pinterest)

Kahit na hindi mo pa narinig ang terminong multimodal embedding, siguradong nagamit mo na ito.
Google Photos: ang kaibigang multimodal lab
I-type ito sa Google Photos:
- "Aso sa niyebe"
- "Birthday cake 2019"
- "Whiteboard na may roadmap"
Lalabas ang nakakagulat na tamang mga larawan, kahit na:
- Ang mga file name ay IMG_9843.JPG.
- Walang sinuman ang nag-type ng "roadmap" kahit saan.
Ang nangyayari sa ilalim ng hood ay konseptwal na katulad ng qwen3 vl embedding setup:
- Ang mga imahe ay ini-encode sa mga vector.
- Ang iyong text query ay ini-encode sa isang vector.
- Hinahanap ng sistema ang mga imahe na may kalapit na mga vector.
Hindi ito "nagbabasa ng isip mo." Gumagamit lang ito ng napaka-densong, napaka-talino na shared math space.
Pinterest visual search: hanapin ito sa pamamagitan ng vibe
Ang visual search ng Pinterest ("hanapin ang mga katulad na pin") ay isa pang magandang halimbawa ng multimodal embedding search.
I-click mo ang isang lampara sa larawan → bigla kang makakakita ng 40 pang ibang lampara sa iba't ibang silid, kulay, at estilo. Ang detalyadong workflow ay iba mula sa qwen3 VL, pero ang pangunahing ideya ay pareho: i-embed ang visual na nilalaman at ikumpara ito sa vector space.
Ito ang dahilan kung bakit maipapakita nito ang:
- Magkakahawig na layout
- Magkakahawig na kulay
- Magkakahawig na damdamin, hindi lang eksaktong tugma
Ang pagkakaiba ngayon: magagawa mo na ito mismo
Ang mga modelo tulad ng qwen3 VL at ang mga katulad nito ay ginagawang isang bagay na maaari mong idagdag sa iyong mga indie na proyekto ang minsang mabigat na imprastraktura na mahika.
Konkretong halimbawa, ang isang pangunahing qwen3 vl embedding workflow para sa sarili mong app ay ganito:
Pag-ingest:
- Kumuha ng mga larawan / PDFs / slides.
- I-run ang mga ito sa isang VL embedding model.
- I-store ang mga vectors sa isang vector DB (hal. Qdrant, Weaviate, Pinecone, pgvector).
Paghahanap:
- Kunin ang text query ng user.
- I-embed gamit ang parehong modelo.
- Gawin ang isang nearest-neighbor search.
Pag-display:
- Ibalik ang orihinal na larawan/slide + anumang kaugnay na metadata.
Sa isang maliit na benchmark na inayos ko para sa isang kliyente (humigit-kumulang 3,500 na design assets at screenshots), ang paglipat mula sa filename/tag search sa isang qwen-style multimodal embedding search:
- Bumababa ang "oras upang mahanap ang tamang asset" ng ~40–60% sa mga pagsubok ng user.
- Mula sa lingguhang "sumuko, ginawang muli ang asset" na mga sandali ay halos zero.
Bakit ito mahalaga para sa personal na AI tools
Narito kung saan nagiging masaya ito para sa mga indie creators, manunulat, at solo SaaS builders: mayroon ka nang maraming multimodal na data. Hindi mo lang ito nasuri ng maayos dati.
Ang iyong totoong-buhay na gulo ay multimodal
Isipin ang iyong workspace:
- Folder ng screenshots (mga ideya sa UI, mga kakompetensya, mga ulat ng bug)
- Mga slide deck (mga presentasyon sa kliyente, materyal ng kurso)
- Mga larawan ng whiteboard (kinunan sa kakaibang mga anggulo, masamang pag-iilaw)
- PDFs (mga ulat, eBooks, invoices)
Ang isang tradisyonal na "AI notes" na tool ay masayang maghahanap ng maliliit na bahagi ng teksto. Ang natitira ay karaniwang madilim na bagay. Sa isang sistemang may qwen3 vl embedding style na nakakabit, biglang ang iyong AI assistant ay maaaring:
- Hanapin ang isang slide na bahagya mong naaalala
- Ilagay ang tamang tsart sa iyong buod para sa kliyente
- Maghanap ng inspirasyon sa UI batay sa isang hindi malinaw na paglalarawan ng teksto
Sa aking sariling setup, nag-wire ako ng maliit na FastAPI service + vector DB + isang qwen-like VL embedding model. Ngayon ay maaari kong:
- Mag-type: "Ang slide kung saan ikinumpara ko ang churn vs activation sa Q2 na may pulang bar."
- Makakuha: Ang tamang slide + dalawang katulad na variant mula sa iba't ibang deck.
Ito lamang ay marahil nakatipid sa akin ng 10–15 minuto bawat araw sa mga paghahanap na "nasaan na ba ang bagay na iyon".
Mas mahusay na personal na RAG systems
Karamihan sa mga tao na nagtatangkang bumuo ng "second brain" sa RAG ay tinatamaan ng parehong hadlang:
Ang aking mga tala ay searchable, ngunit ang mga kawili-wiling bagay ay naninirahan sa mga screenshot at slide.
Isang qwen3 vl embedding workflow para sa personal na kaalaman ay ganito:
I-index ang lahat:
- Mga text file → mga text embeddings.
- Mga imahe/slide/PDFs → VL embeddings.
I-link ang mga modality:
- I-imbak ang mga sanggunian upang ang bawat imahe ay tumuturo sa mga kaugnay na piraso ng teksto (mga caption, tala ng pulong, mga bahagi ng dokumento).
Sa oras ng tanong:
- I-embed ang tanong gamit ang parehong text at VL models (o VL lamang kung shared).
- Kunin ang parehong kaugnay na teksto at mga imahe.
- Ibigay ang lahat sa isang LLM (ideally multimodal) para sumagot.
Makakakuha ka ng mga kasagutan tulad ng:
"Narito ang iyong Q2 churn vs activation slide, at base sa tsart, ang activation rate mo ay umangat mula sa ~26% hanggang ~34% sa pagitan ng Abril at Hunyo. Ang note na isinulat mo sa tabi nito ay nagsasabing ang pagbabago ay dahil sa mga bagong onboarding experiments."
Sa halip na:
"Wala akong nahanap na may kaugnayan."
Mas tapat na trade-offs
Hindi ito puro magic. May ilang totoong limitasyon na naranasan ko habang sinusubok ang qwen-style VL embeddings:
- Maliit na teksto sa mga imahe ay maaari pa ring maging magaspang. Ang maliliit na axis labels o siksik na mga talahanayan ay hindi palaging maganda ang labas.
- Lubos na abstract na mga query tulad ng "slide kung saan ako nahirapan" ay malinaw na hindi gagana.
- Mga diagram na partikular sa isang domain (hal., mga natatanging engineering notations) ay maaaring mangailangan ng masusing pag-tune o hybrid na pamamaraan.
Ngunit kahit na may mga caveat na ito, ang pagtalon mula sa "text lang ang searchable" patungo sa "text + visuals ay may iisang kahulugan na espasyo" ay sapat na malaki upang ngayon ay nag-aalangan akong gumamit ng anumang personal na AI tool na hindi nag-aalok ng kahit anong uri ng multimodal embedding search.
Ano ang susunod para sa teknolohiyang ito

Kung titingnan natin mula sa malayo, ang qwen3 vl embedding ay bahagi ng mas malaking trend: ang mga modelo ay nagiging mas mahusay sa pag-unawa sa mundo (sa kabila ng teksto, mga imahe, at marahil audio/video) sa isang solong, buo na espasyo.
Narito kung saan ko nakikita ito papunta sa susunod na 12–24 na buwan, base sa kung paano na nagbabago ang mga bagay.
1. Multimodal embeddings na naka-integrate sa mas maraming tools bilang default
Sa kasalukuyan, madalas kailangan mong pagsamahin ang mga bagay-bagay:
- Pumili ng VL model
- Pumili ng vector DB
- Isulat ang ingestion pipeline
Inaasahan kong mas maraming tools ang maglalabas ng built-in multimodal embedding search:
- Mga note apps na awtomatikong nag-iindex ng iyong mga nai-paste na screenshots
- Mga project tools na ginagawang searchable ang mga larawan ng meeting base sa nilalaman ng whiteboard
- Mga asset managers na "nakakaintindi" ng layout, kulay, at istruktura ng UI
Kapag nangyari ito, titigil na ang mga tao sa pagsabi ng "vector DB" at "VL model" at sasabihin na lang, "oo, pwede ko nang hanapin ang mga bagay ko gamit ang paglalarawan."
2. Mas mahigpit na ugnayan sa pagitan ng retrieval at generation
Sa ngayon, marami pa ring RAG setups na gaya ng:
- Embed
- Retrieve
- Itapon sa isang LLM
Nakikita ko na ang mga prototype (kasama ang ilang qwen-style stacks) kung saan ang model:
- Gumagamit ng multimodal embeddings para planuhin kung anong uri ng context ang kailangan nito
- Humihingi ng mas maraming larawan o teksto kung mahina ang unang batch
- Muling inuuri ang mga resulta gamit ang isang hiwalay na relevance model
Sa sarili kong mga eksperimento, ang pagdaragdag ng simpleng re-ranking step sa ibabaw ng base multimodal embedding search ay nagpa-improve ng "top-1 ay talagang iyon ang gusto ko" mula sa humigit-kumulang 78% hanggang sa mga 90% para sa aking slide + screenshot dataset.
3. Personal na "visual memory" para sa mga creators
Para sa mga indie creators at marketers partikular, isang magandang direksyon ay ang visual memory layer:
- Bawat thumbnail na sinubukan mo
- Bawat ad creative na ginamit mo
- Bawat slide na ipinakita mo
- Bawat variant ng landing page na inilabas mo
Lahat ay naka-embed nang isang beses sa pamamagitan ng qwen3 vl embedding workflow, para maaari mong itanong sa huli:
- "Ipakita mo sa akin ang mga ad creatives na katulad ng mga nakakuha ng >5% CTR."
- "Hanapin ang mga nakaraang thumbnail kung saan gumamit ako ng madilim na background at orange na teksto."
- "Anong mga layout ang ginamit ko sa mga landing page na nag-convert ng >8%?"
Itali iyan sa analytics, at hindi ka lang naghahanap ng mga visual, naghahanap ka ng mga nagpeperform na visual.
4. Mga panganib at mga bagay na dapat bantayan
Para manatiling nakabatay sa realidad, narito ang ilang bagay na maingat ako tungkol sa kapag sinusubukan at inirerekomenda ko ang mga multimodal embedding stacks:
- Pribado: Ang pagpapadala ng mga screenshot at slide sa third-party API ay madalas na hindi pwede para sa mga gawaing kliyente. Ang self-hostable VL models (kasama ang qwen-style) ay magiging napakahalaga dito.
- Gastos: Ang pag-embed ng libu-libong mga imahe ay hindi libre. Isang beses na pag-index ay karaniwang okay, pero kung mayroon kang live video frames o madalas na pag-update, kailangan mong bantayan ang mga token at GPU bills.
- Pagsusuri: Madaling mag-akala na maganda ang paghahanap. Mas mabuting subaybayan ang:
- Top-1 accuracy sa isang labeled query set
- "Oras sa asset" sa iyong pang-araw-araw na trabaho
- Gaano kadalas ka pa rin sumusuko at muling lumilikha ng isang bagay

Ang aking rekomendasyon kung ikaw ay interesado
Kung ikaw ay kasalukuyang gumagamit ng mga AI tools, ang aking tapat na rekomendasyon ay: subukan mong gumawa ng isang maliit na eksperimento gamit ang multimodal embeddings.
Kunin ang isang tambak ng visual na kalat — folder ng mga screenshot, archive ng mga slide, mga export ng Pinterest board, at iba pa. Ikonekta ang isang simpleng qwen3 vl embedding search sa mga ito. Gumamit ng isang vector DB, o kahit isang on-disk index para sa pagsubok.
Bigyan mo ang iyong sarili ng isang linggo para aktwal na mag-query nito na parang isang tao:
- "Yung slide kung saan…"
- "Yung dashboard na nagpakita…"
- "Yung ad na may asul na background at nagulat na mukha…"
Kung ang iyong karanasan ay katulad ng sa akin, titigil ka nang isipin ang embeddings bilang isang boring na infra term at magsisimulang isipin ito bilang pagkakaiba ng 'ang aking mga bagay ay isang itim na butas' at 'ang aking mga bagay ay isang extension ng aking memorya.'
At kapag nangyari iyon, mahirap nang bumalik.
Tungkol sa modelo: Ang Qwen3-VL-Embedding ay inilabas noong Enero 8, 2026, ng Qwen team ng Alibaba. Sinusuportahan nito ang mahigit 30 wika at nakamit ang state-of-the-art na mga resulta sa multimodal benchmarks tulad ng MMEB-v2 (79.2 overall score) at MMTEB (74.9 sa reranker). Ang modelo ay open-source at makukuha sa Hugging Face, GitHub, at ModelScope.